

一、前言(可跳过)
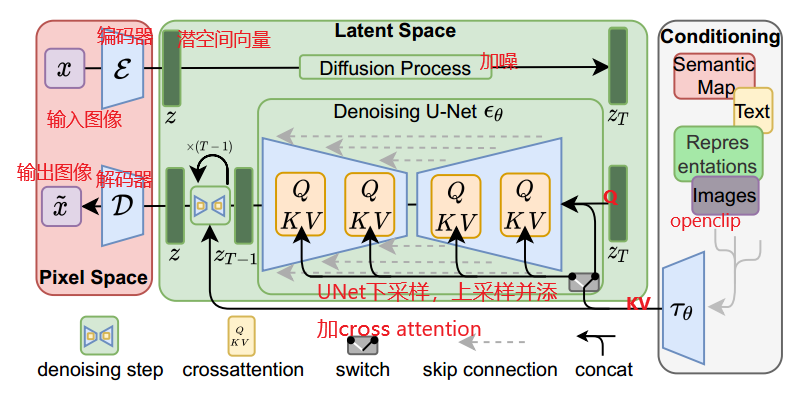
二、stable diffusion
对于上面原论文的图片可能小伙伴理解有困难,但是不打紧,我会把上面图片分成一个个单独的模块进行解读,最后组合在一起,相信你们一定可以理解图片每一步干了什么事。
首先,我会画一个简化模型图对标原图,以方便理解。让我们从训练阶段开始,可能你们发现少了VAEdecoder,这是因为我们训练过程是在潜空间完成,decoder我们放在第二阶段采样阶段说,我们所使用的stablediffusion webui画图通常是在采样阶段,至于训练阶段,目前我们大多数普通人是根本完成不了的,它所需要训练时间应该可以用GPUyear来计量,(单V100的GPU要一年时间),如果你有100张卡,应该可以一个月完成。至于ChatGPT光电费上千万美金,上万GPU集群,感觉现在AI拼的就是算力。又扯远了,come back
1.clip
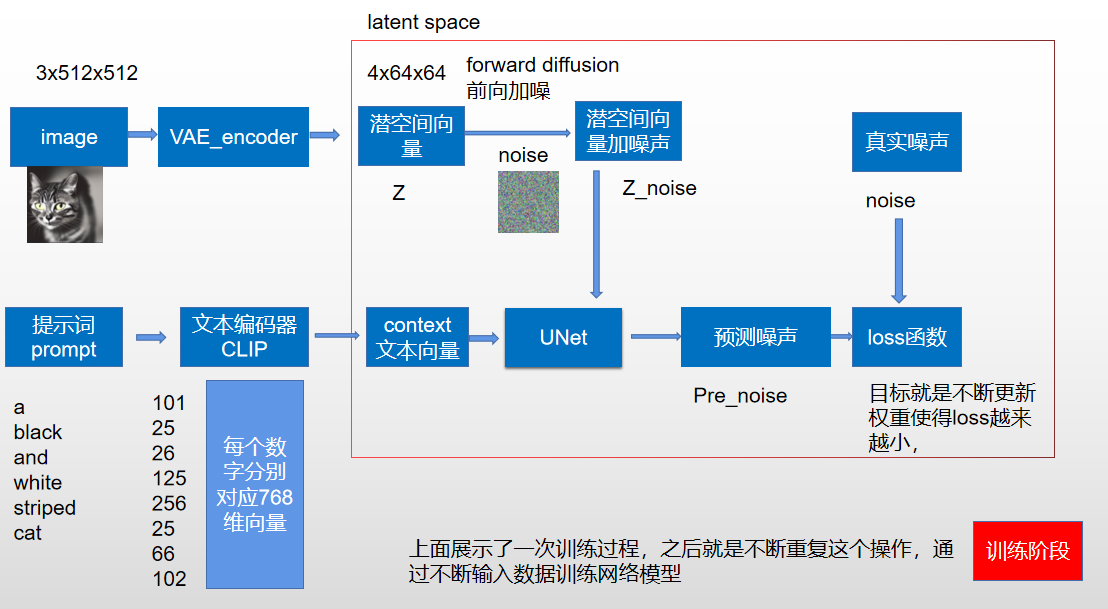
我们先从提示词开始吧,我们输入一段提示词a black and white striped cat(一条黑白条纹的猫),clip会把文本对应一个词表,每个单词标点符号都有相对应的一个数字,我们把每个单词叫做一个token,之前stablediffusion输入有限制只能75个单词(现在没了),也就是75个token,看上面你可能发现6个单词怎么对应8个token,这是因为还包含了起始token和结束token,每个数字又对应这一个768维的向量,你可以看作每个单词的身份证,而且意思非常相近的单词对应的768维向量也基本一致。经过clip我们得到了一个(8,768)的对应图像的文本向量。
stable diffusion所使用的是openAi的clip的预训练模型,就是别人训练好的拿来用就行,那clip是怎么训练出来的呢?他是怎么把图片和文字信息对应呢?(下面扩展可看可跳过,不影响理解,只需要知道它是用来把提示词转成对应生成图像的文本向量即可)
CLIP需要的数据为图像及其标题,数据集中大约包含4亿张图像及描述。应该是直接爬虫得来,图像信息直接作为标签,训练过程如下:
CLIP 是图像编码器和文本编码器的组合,使用两个编码器对数据分别进行编码。然后使用余弦距离比较结果嵌入,刚开始训练时,即使文本描述与图像是相匹配的,它们之间的相似性肯定也是很低的。
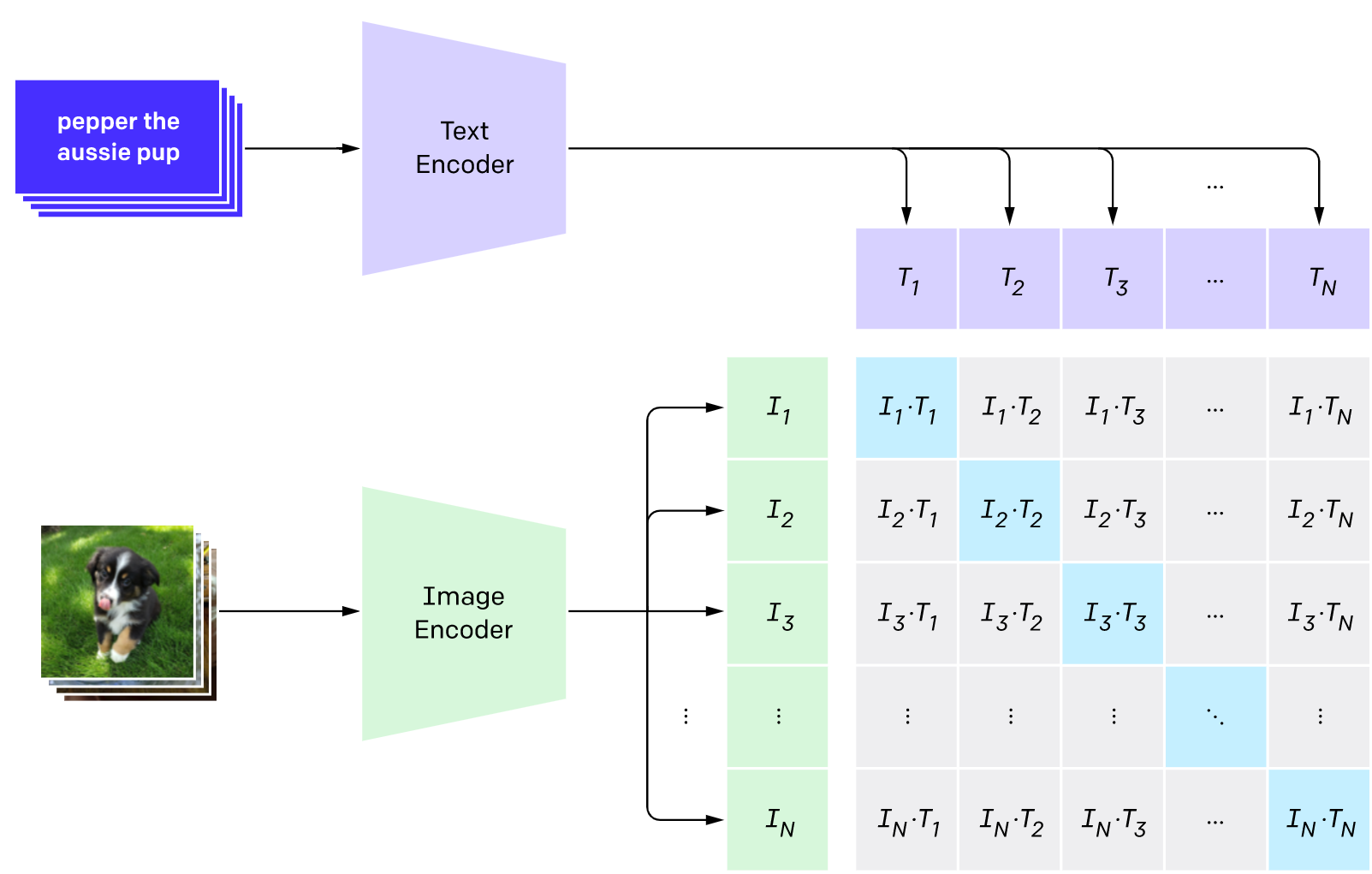
随着模型的不断更新,在后续阶段,编码器对图像和文本编码得到的嵌入会逐渐相似。在整个数据集中重复该过程,并使用大batch size的编码器,最终能够生成一个嵌入向量,其中狗的图像和句子「一条狗的图片」之间是相似的。
给一些提示文本,然后每种提示算相似度,找到概率最高的即可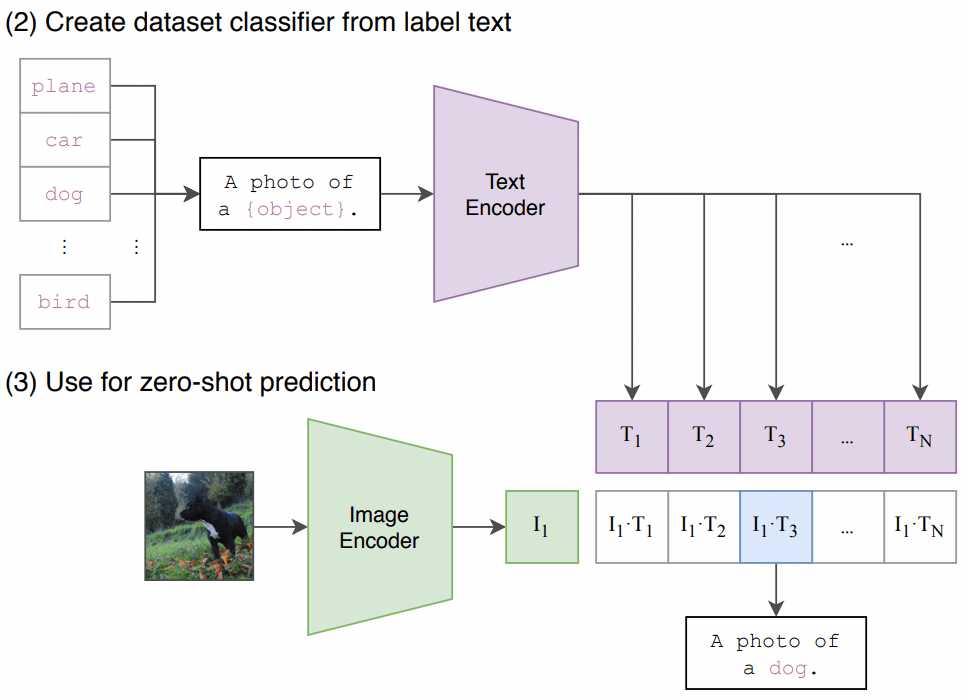
2.diffusion model
上面我们已经得到了unet的一个输入了,我们现在还需要一个噪声图像的输入,假如我们输入的是一张3x512x512的猫咪图像,我们不是直接对猫咪图像进行处理,而是经过VAE encoder把512x512图像从pixel space(像素空间)压缩至latent space(潜空间)4x64x64进行处理,数据量小了接近64倍。
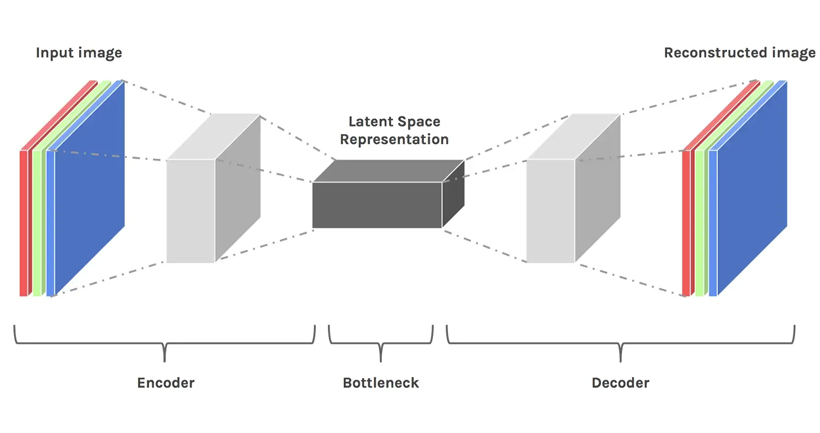
潜在空间简单的说是对压缩数据的表示。所谓压缩指的是用比原始表示更小的数位来编码信息的过程。维度降低会丢失一部分信息,然而在某些情况下,降维不是件坏事。通过降维我们可以过滤掉一些不太重要的信息你,只保留最重要的信息。
得到潜空间向量后,现在来到扩散模型,为什么图像加噪后能够还原,秘密都在公式里,这里我以DDPM论文作为理论讲解,论文,当然还有改进版本DDIM等等,感兴趣自己看
forward diffusion (前向扩散)
- 首先是forward diffusion (前向扩散),也就是加噪过程,最后就快变成了个纯噪声
- 每一个时刻都要添加高斯噪声,后一时刻都是由前一刻是增加噪声得到

那么是否我们每一次加噪声都要从前一步得到呢,我们能不能想要第几步加噪图像就能得到呢?答案是YES,作用是:我们训练过程中对图像加噪是随机的,假如 我们随机到100步噪声,(假设设置时间步数200步),如果要从第一步加噪,得到第二步,循环往复,太费时间了,其实这些加的噪声有规律的,我们现在的目标就是只要有原始图像X0,就可以得到任意时刻图像加噪声的图像,而不必一步一步得到想要的噪声图像。

我来对上述作讲解,其实该标住的我都标的很清楚了,
第一,αt范围0.9999-0.998,
第二,图像加噪是符合高斯分布的,也就是在潜空间向量加的噪声是符合均值为0,方差为1的,将Xt-1带入Xt中,为什么两项可以合并,因为Z1Z2都是符合高斯分布,那么他们相加Z2'也符合,并且它们的方差和为新的方差,所有把他们各自的方差求和,(那个带根号的是标准差),如果你无法理解,可以把它当做一个定理。在多说一句,对Z-->a+bZ,那么Z的高斯分别也从(0,σ)-->(a,bσ),现在我们得到了Xt跟Xt-2的关系
第三,如果你再把Xt-2带入,得到与Xt-3的关系,并且找到规律,就是α的累乘,最后得到Xt与X0的关系式,现在我们可以根据这个式子直接得到任意时刻的噪声图像。
第四,因为图像初始化噪声是随机的,假设你设置的时间步数(timesteps)为200,就是把0.9999-0.998区间等分为200份,代表每个时刻的α值,根据Xt和X0的公式,因为α累乘(越小),可以看出越往后,噪声加的越快,大概1-0.13的区间,0时刻为1,这时Xt代表图像本身,200时刻代表图像大概α为0.13噪音占据了0.87,因为是累乘所以噪声越加越大,并不是一个平均的过程。
第五,补充一句,重参数化技巧(Reparameterization Trick)
如果X(u,σ2),那么X可以写成X=μ十σZ的形式,其中Z~Ν(0,1)。这就是重参数化技巧。
重参数化技巧,就是从一个分布中进行采样,而该分布是带有参数的,如果直接进行采样(采样动作是离散的,其不可微),是没有梯度信息的,那么在BP反向传播的时候就不会对参数梯度进行更新。重参数化技巧可以保证我们从进行采样,同时又能保留梯度信息。
逆向扩散(reverse diffusion)
- 前向扩散完毕,接下来是逆向扩散(reverse diffusion),这个可能比上面那个难点,如何根据一个噪声图像一步步得到原图呢,这才是关键,
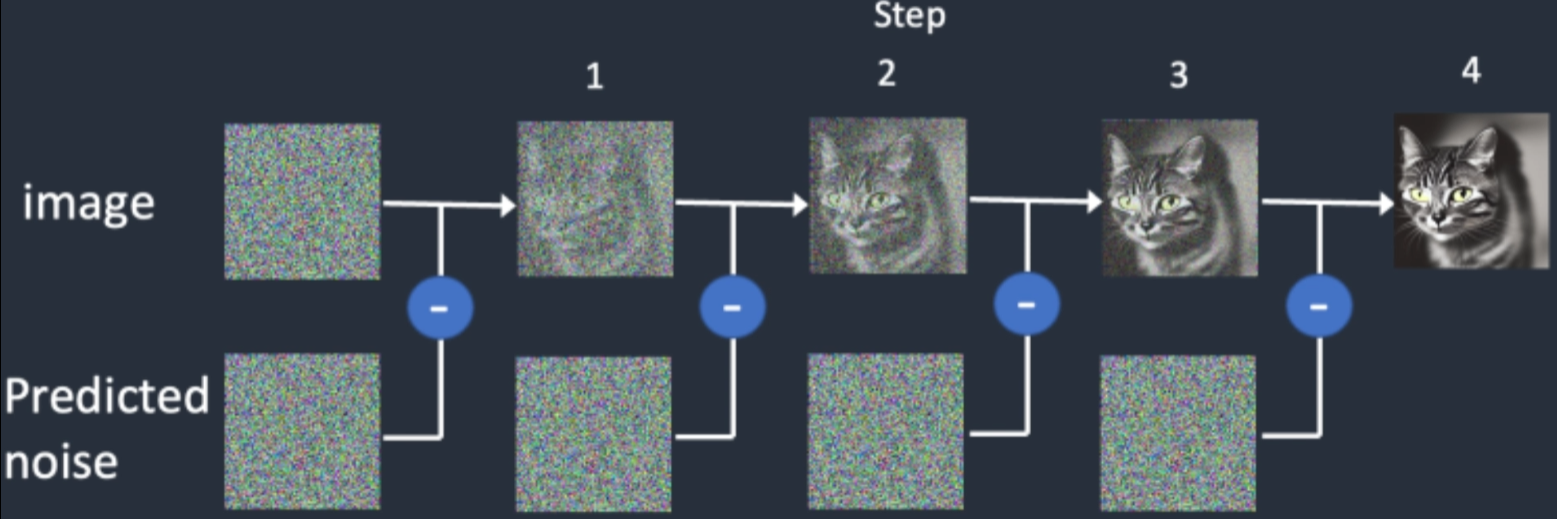
- 逆向开始,我们目标是Xt噪声图像得到无噪声的X0,先从Xt求Xt-1开始,这里我们先假设X0是已知(先忽略为什么假设已知),后面会替换它,至于怎么替换,前向扩散不是已知Xt和X0的关系吗,现在我们已知的是Xt,反过来用Xt来表示X0,但是还有一个Z噪声是未知的,这个时候就要Unet上场了,它需要把噪声预测出来。
- 这里借助贝叶斯公式(就是条件概率),我们借助贝叶斯公式结果,以前写过一个文档

就是已知Xt求Xt-1,反向我们不知道怎么求,但是求正向,如果我们已知X0那么这几项我们都可以求出来。
开始解读,既然这三项都符合高斯分别,那带入高斯分布(也可以叫正态分布),它们相乘为什么等于相加呢,因为e2 * e3 =e2+3,这个能理解吧(属于exp,就是e次方),好,现在我们得到了一个整体式子,接下来继续化简
首先我们把平方展开,未知数现在只有Xt-1,配成AX2+BX+C格式,不要忘了,即使相加也是符合高斯分布,现在我们把原高斯分别公式配成一样的格式,红色就是方差的倒数,把蓝色乘方差除2就得到了均值μ(下面显示是化简的结果,如果你有兴趣自己,自己化简),回归X0,之前说X0假设已知,现在转成Xt(已知)表示,代入μ,现在未知数只剩下Zt,
- Zt其实就是我们要估计的每个时刻的噪声
- 这里我们使用Unet模型预测
- 模型的输入参数有三个,分别是当前时刻的分布Xt和时刻t,还有之前的文本向量,然后输出预测的噪声,这就是整个过程了,

- 上面的Algorithm 1是训练过程,
其中第二步表示取数据,一般来说都是一类猫,狗什么的,或者一类风格的图片,不能乱七八糟什么图片都来,那模型学不了。
第三步是说每个图片随机赋予一个时刻的噪声(上面说过),
第四步,噪声符合高斯分布,
第五步,真实的噪声和预测的噪声算损失(DDPM输入没有文本向量,所有没有写,你就理解为多加了一个输入),更新参数。直到训练的输出的噪声和真实噪声相差很小,Unet模型训练完毕
- 下面我们来到Algorithm2采样过程
- 不就是说Xt符合高斯分布嘛
- 执行T次,依次求Xt-1到X0,不是T个时刻嘛
- Xt-1不就是我们逆向扩散推出的公式,Xt-1=μ+σZ,均值和方差都是已知的,唯一的未知噪声Z被Unet模型预测出来,εθ这个是指已经训练好的Unet,
采样图
- 为了方便理解,我分别画出文生图和图生图,如果使用stable diffusion webui画图的人一定觉得很熟悉,如果是文生图就是直接初始化一个噪声,进行采样,
- 图生图则是在你原有的基础上加噪声,噪声权重自己控制,webui界面是不是有个重绘幅度,就是这个,
- 迭代次数就是我们webui界面的采样步数,
- 随机种子seed就是我们初始随机得到的一个噪声图,所以如果想要复刻得到一样的图,seed要保持一致
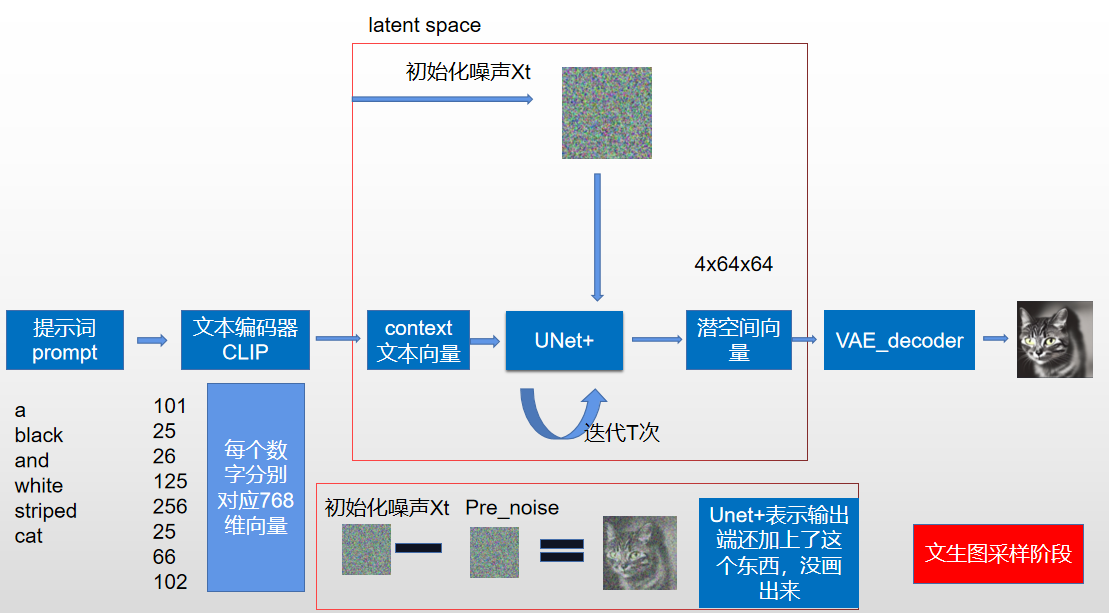
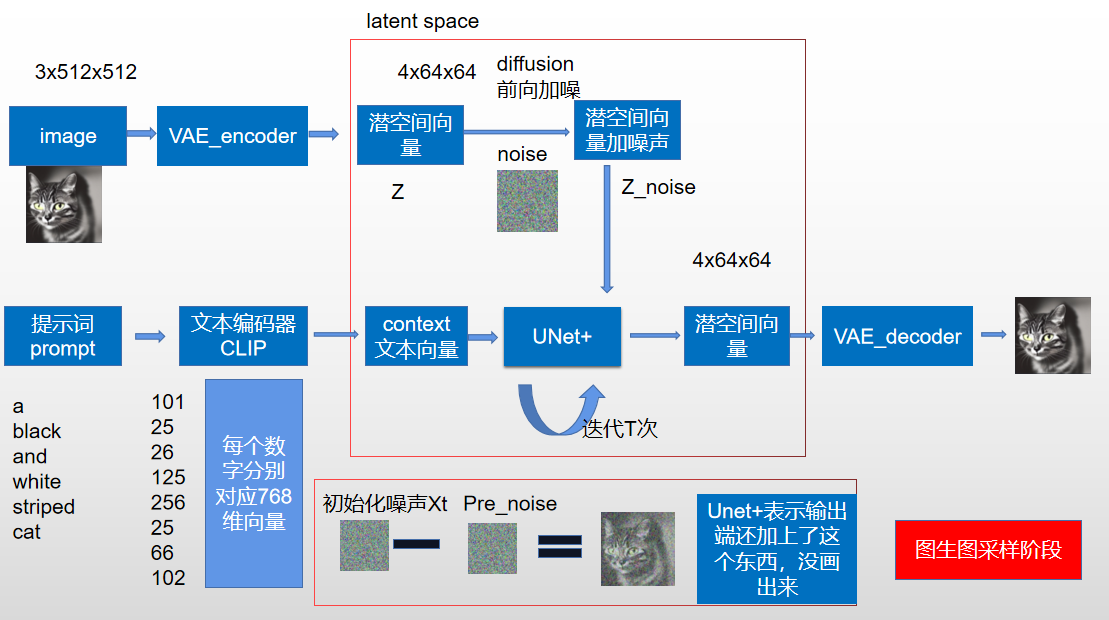
阶段小结
我们现在再来看这张图,除了Unet我没讲(下面会单独介绍),是不是简单多了,最左边不就是像素空间的编码器解码器,最右边就是clip把文本变成文本向量,中间上面的就是加噪,下面就是Unet预测噪声,然后不停的采样解码得到输出图像。这是原论文采样图,没画训练过程。
3.Unet model
unet模型相信小伙伴们都或多或少知道,就是多尺度特征融合,像FPN图像金字塔,PAN,很多都是差不多的思想,一般使用resnet作为backbone(下采样),充当编码器,这样我们就得到多个尺度的特征图,然后在上采样过程中,上采样拼接(之前下采样得到的特征图),上采样拼接,这是一个普通的Unet

那stablediffusion的Unet有什么不一样呢,这里找到一张图,佩服这位小姐姐有耐心,借一下她的图
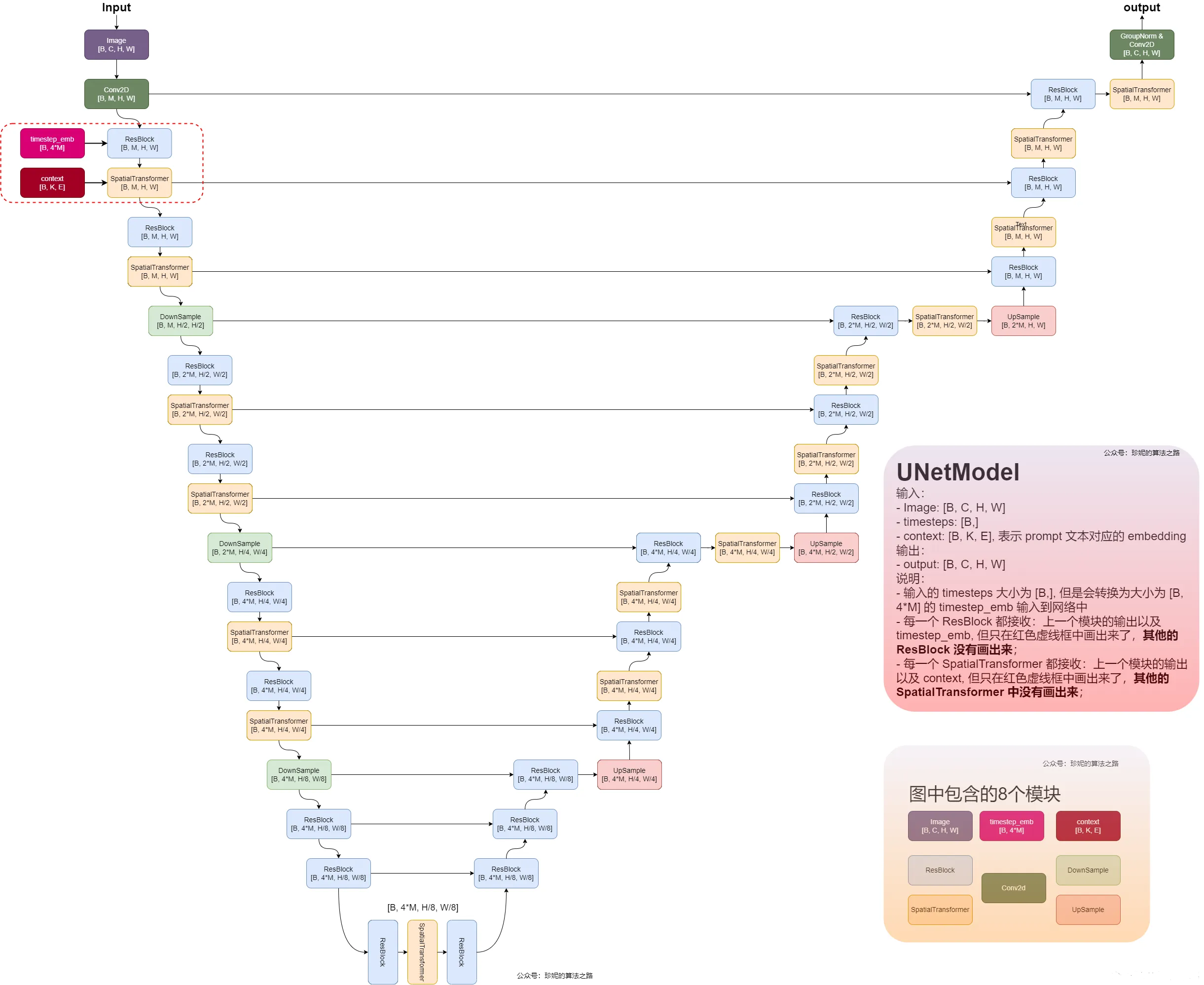
我解释一下和ResBlock模块和SpatialTransformer模块,输入为timestep_embedding,context 以及input就是三个输入分别是时间步数,文本向量,加噪图像,时间步数你可以理解为transformer里的位置编码,在自然语言处理中用来告诉模型一句话每个字的位置信息,不同的位置可能意思大不相同,而在这,加入时间步数信息,可以理解为告诉模型加入第几步噪声的时刻信息(当然这是我的理解)。
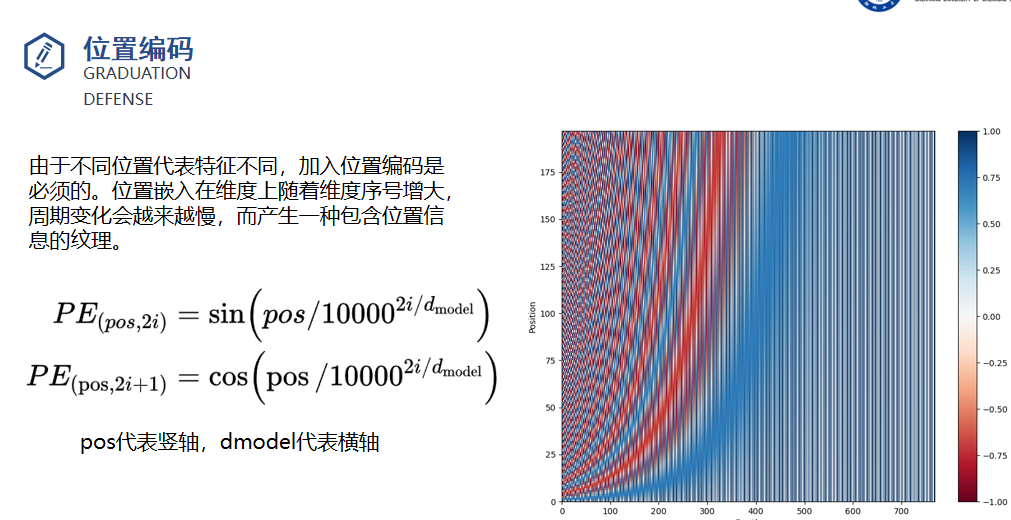
timestep_embedding采用正余弦编码
ResBlock模块输入为时间编码和卷积后图像输出,把它们相加,这就是它的作用,具体细节不说了,就是卷积,全连接,这些很简单。
SpatialTransformer模块输入为文本向量和上一步ResBlock的输出,
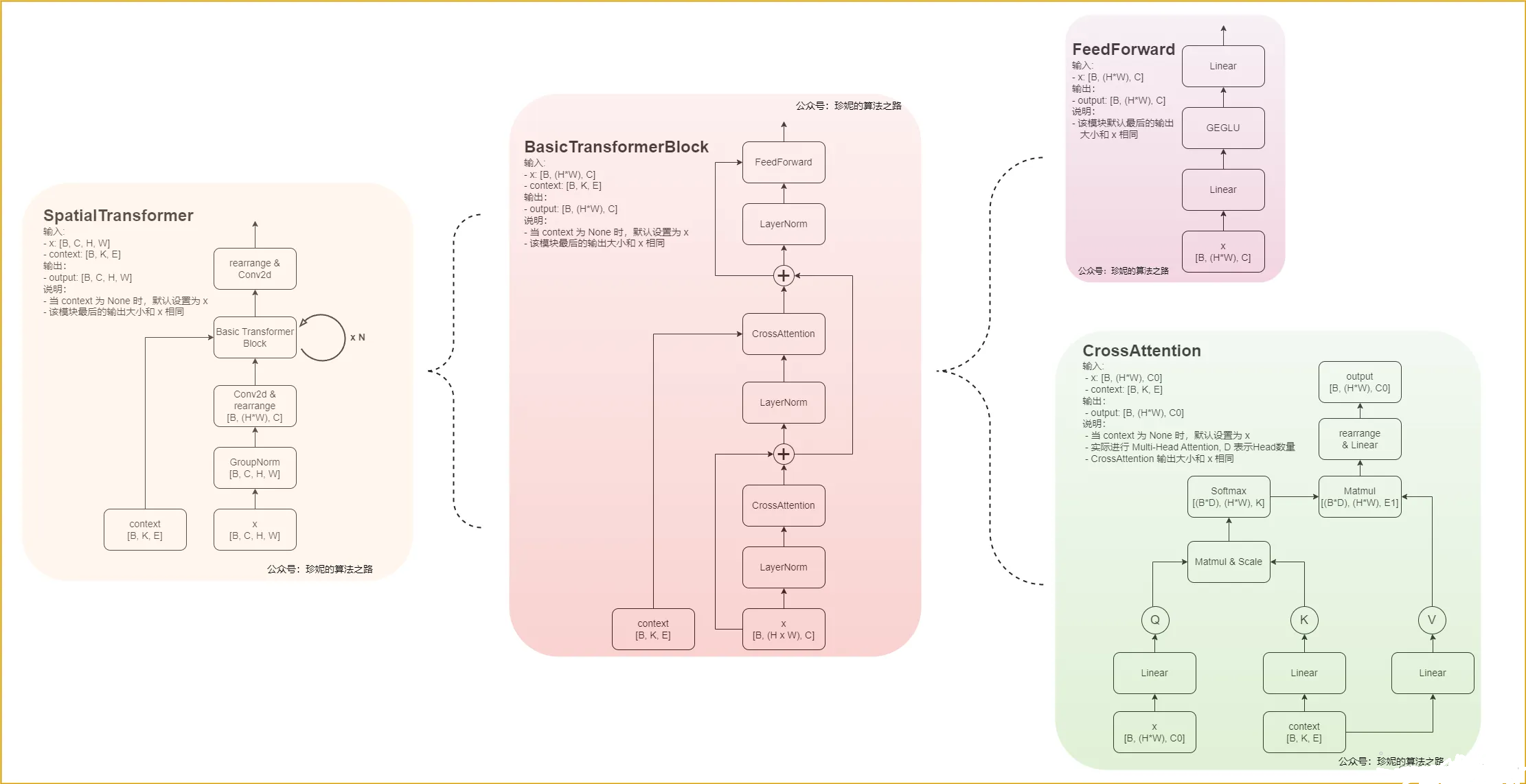
里面主要讲一下cross attention,其他都是一些维度的变换,卷积操作和各种归一化Group Norm,Layer norm,
利用cross attention将latent space(潜空间)的特征与另一模态序列(文本向量)的特征融合,并添加到diffusion model的逆向过程,通过Unet逆向预测每一步需要减少的噪音,通过GT噪音与预测噪音的损失函数计算梯度。
看右下角图,可以知道Q为latent space(潜空间)的特征,KV则都是文本向量连两个全连接得到,剩下就是正常的transformer操作了,QK相乘后,softmax得到一个分值,然后乘V,变换维度输出,你可以把transformer当做一个特征提取器,它可以把重要信息给我们显现出来(仅帮助理解),差不多就是这样了,之后操作都差不多,最后输出预测的噪声。
这里你肯定得熟悉transformer,知道什么是self attention,什么是cross attention不懂找篇文章看看,感觉不是可以简单解释清楚的。
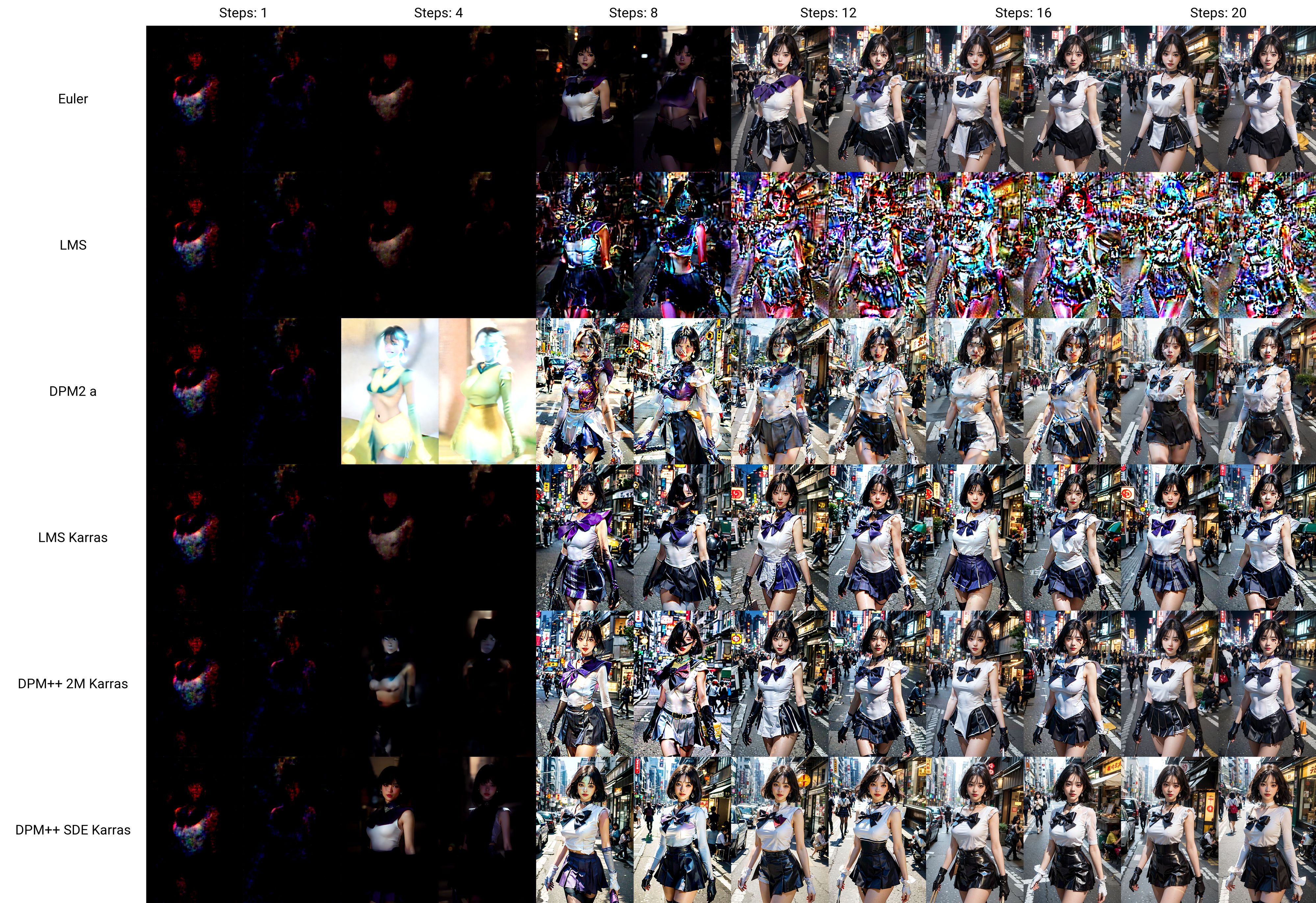
完毕,拜拜,显示一些webui对比图
三、stable diffusion webui扩展
参数clip



评论