


前言
-
零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
-
少样本 TTS:
-
跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
-
WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
使用
安装
https://github.com/RVC-Boss/GPT-SoVITS?tab=readme-ov-file

同时下载权重文件放入相应文件夹

如果网速不好,怕麻烦,百度网盘:
链接: https://pan.baidu.com/s/1jeub2AzO6SeGge_YTimirQ 提取码: 2qkp
准备数据
虽然几分钟即可训练,但是声音数据半个小时到一个小时更好,吐字清晰,格式最好WAV
解压后双击 go-webui.bat 即可启动 GPT-SoVITS-WebUI
来到页面,勾选开启UVR5,自动跳转webui(如果你的数据有杂音和伴奏)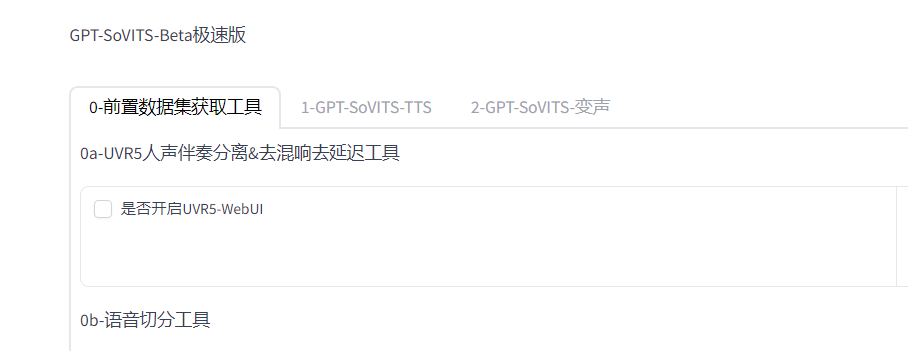
去伴奏
填入你音频文件路径或拖拽你的文件,HP2伴奏分离,然后依次是人声与伴奏声保存路径,导出格式WAV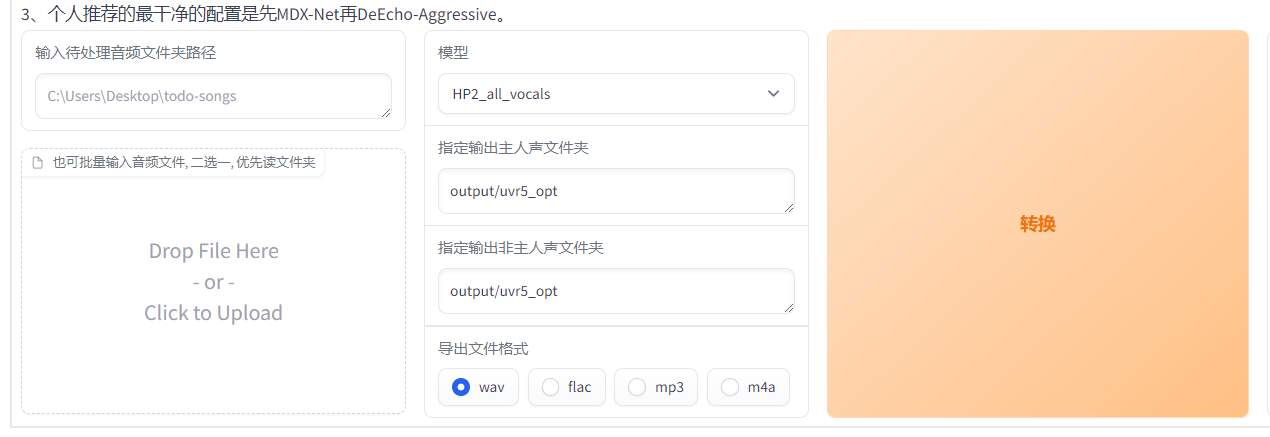
然后文件就在改路径下vocal(人声)
去混响延时
输入去玩伴奏的人声音频路径,输出依然是哪个文件夹下带vocal(人声)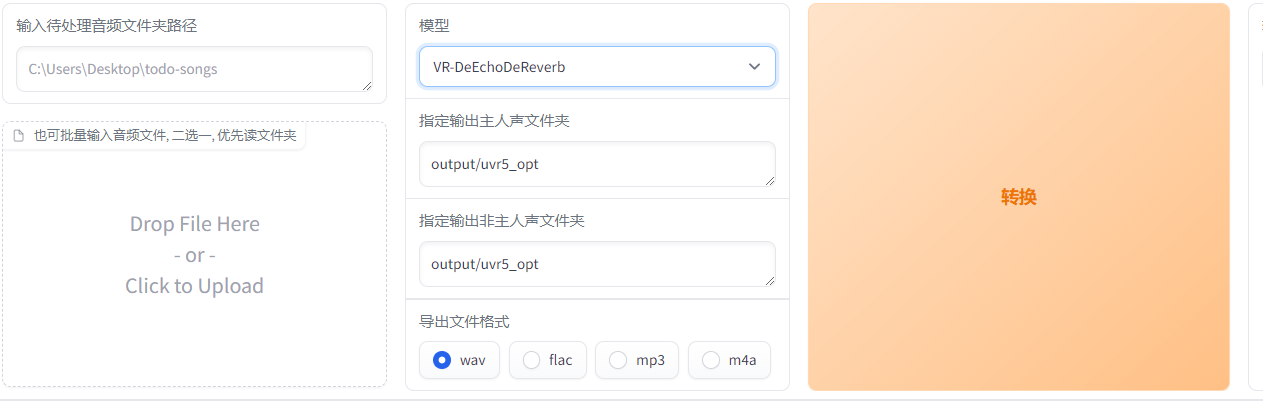
xiaoqi_train.wav我改名的去伴奏去混响最终文件
分割音频
关闭UVR5,切分音频,填入文件路径,其他默认
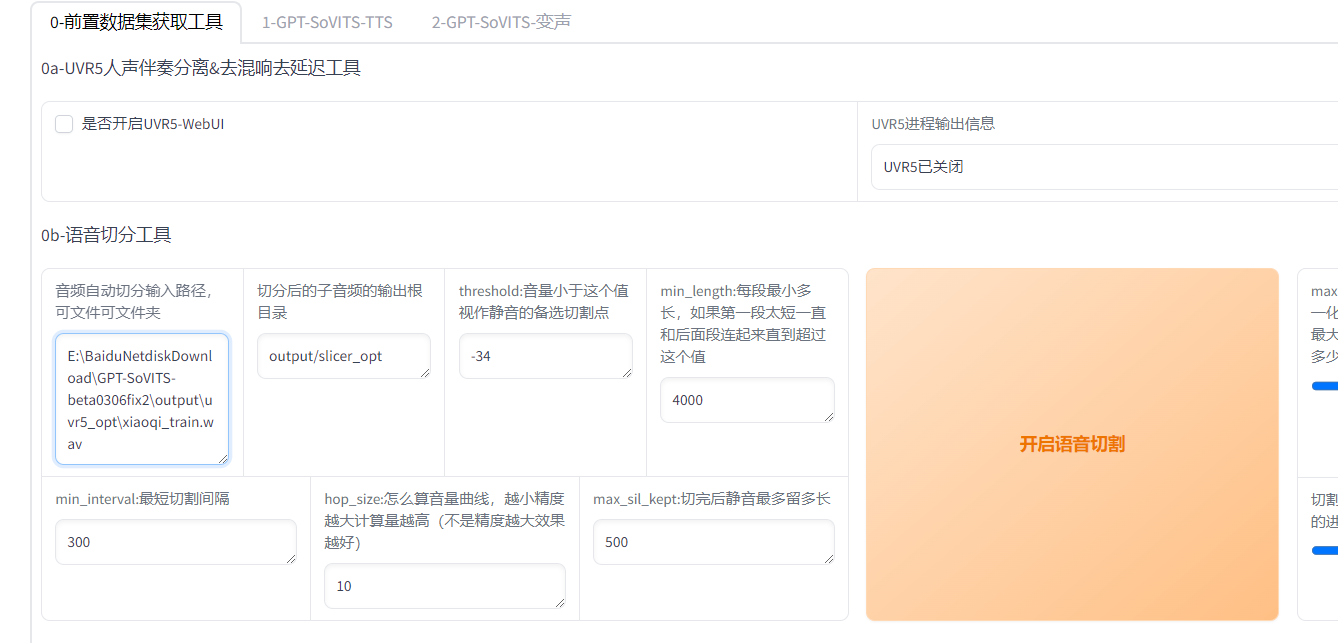
降噪
输入切分的文件夹路径

ASR
输入降噪后音频文件,中文选达摩,英文whisper
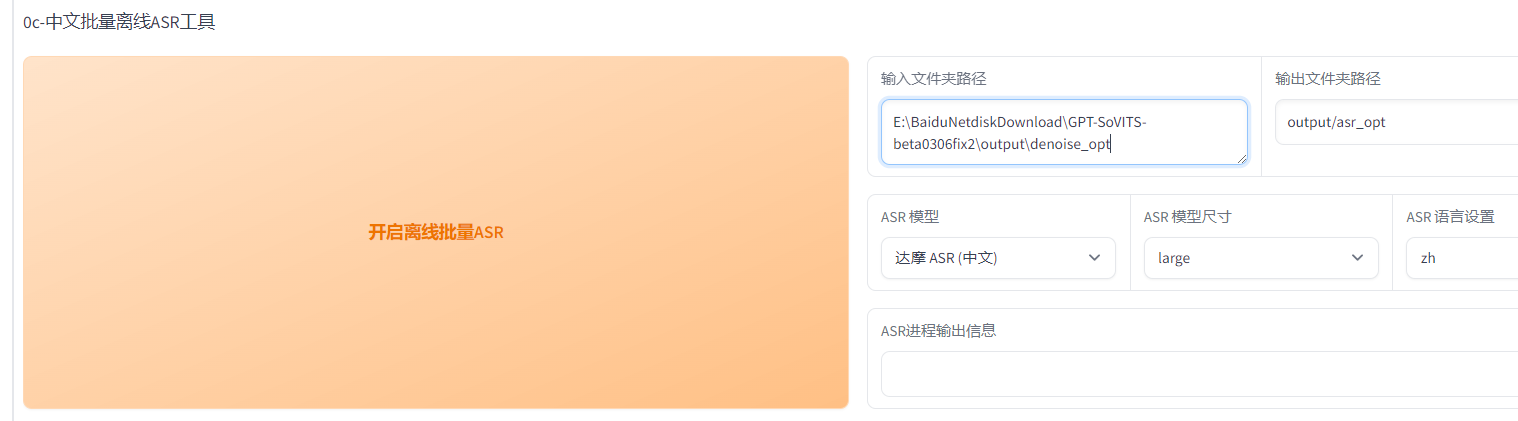
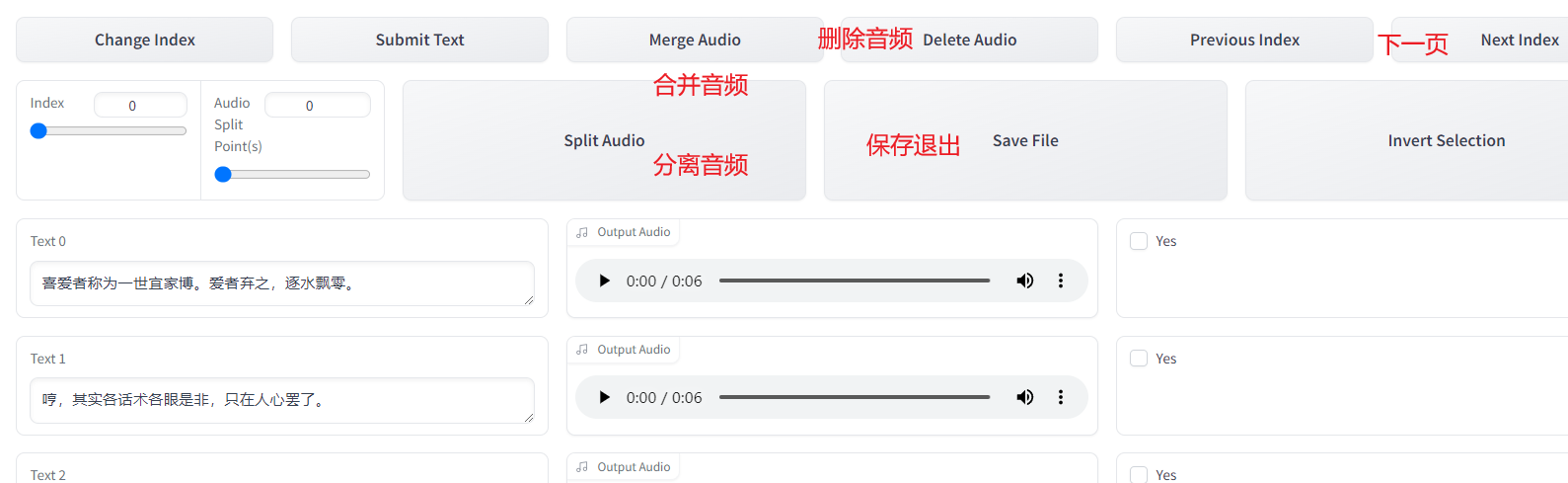
数据清洗
勾选webui,输入ASR输出文件路径

主要这几个就够用了,修改文字对应音频,删除一些杂乱语音,合并一些过短语音,最后保存退出
训练集格式化
填入实验名和路径,其他默认
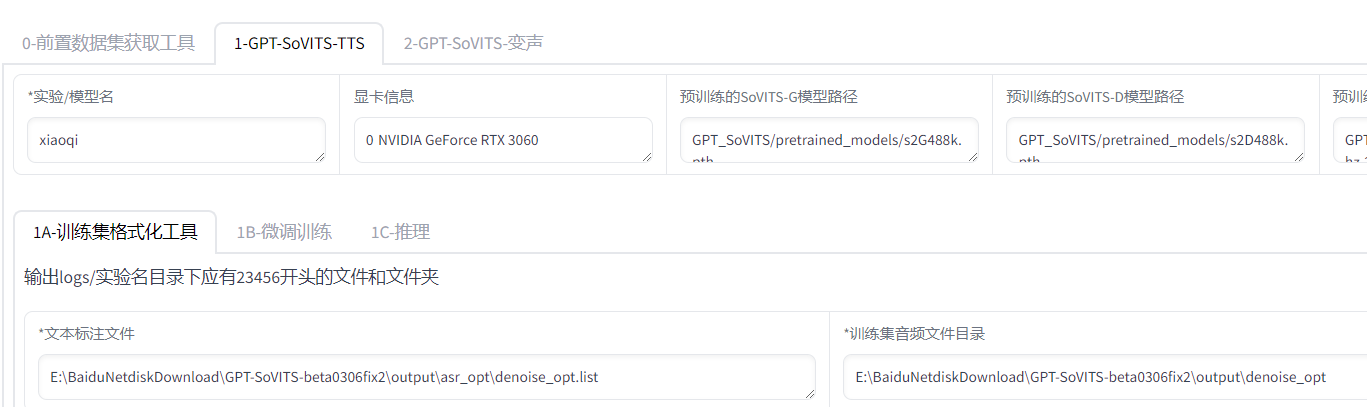
点击一键三连,一次全部运行(E:\BaiduNetdiskDownload\GPT-SoVITS-beta0306fix2\logs\xiaoqi生成五个文件)
微调训练
8G显存,按照我这个设置,时长几分钟,SOVITS训练轮数25以下够了,时长抄半小时,语音吐字清晰,训练轮数100,200都可以,学习率权重适当降低,否则默认,显卡大于8G,batch size可以加大,GPT训练25轮一般效果不错
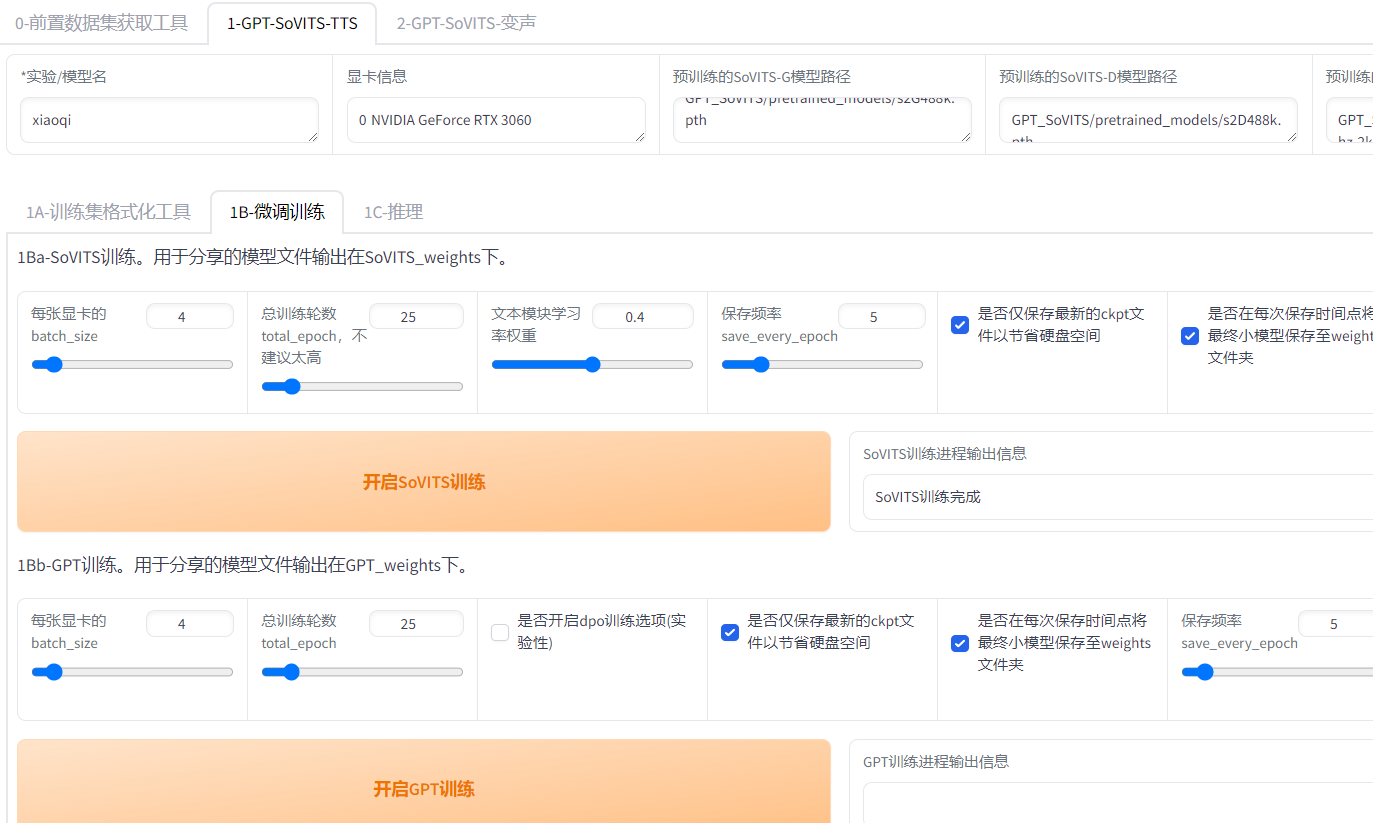
训练上线无法超过25问题解决,编辑器打开webui.py
大概830行左右,修改200即可

模型路径
推理
勾选TTS webui
来到
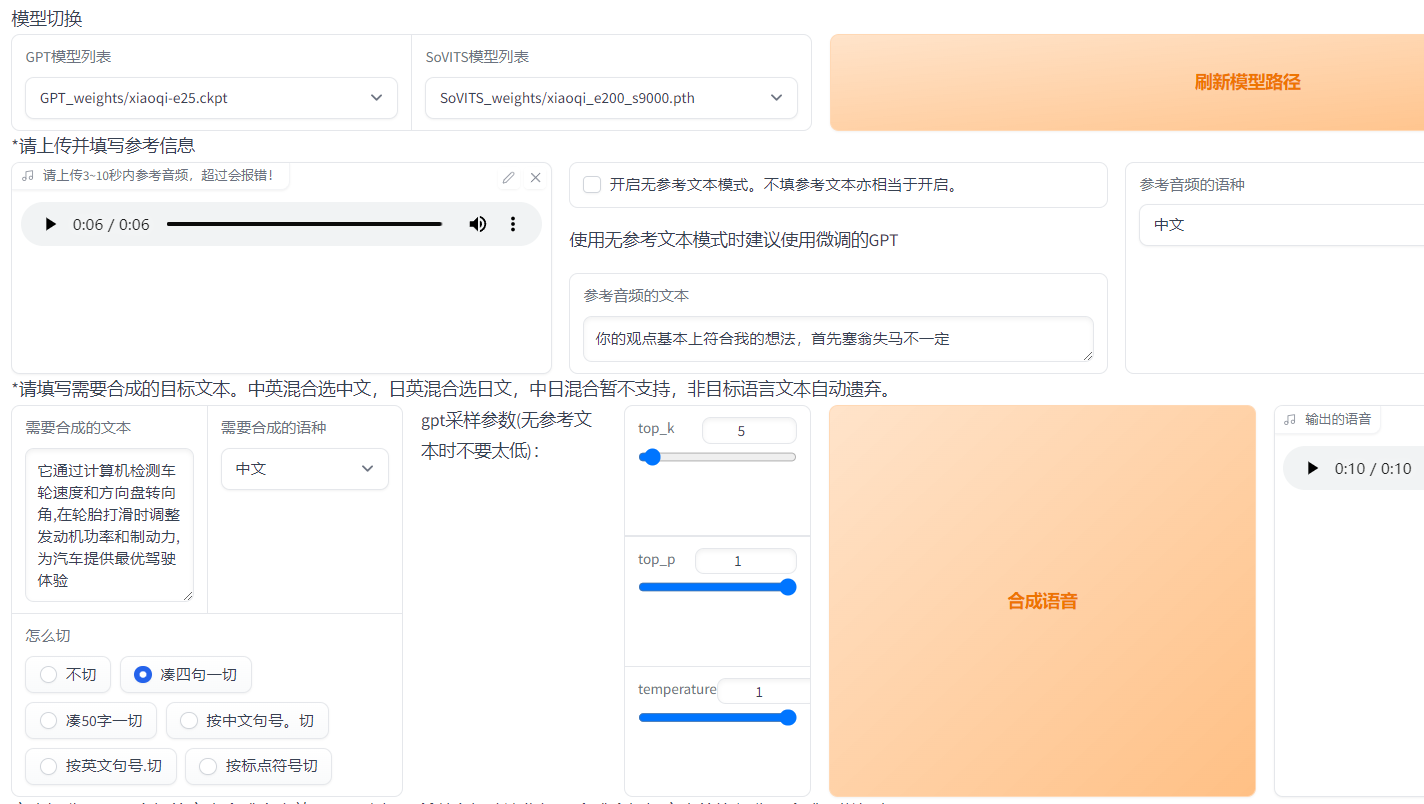
GPT25轮效果不错,SOVITS选择轮数最高的,因为我音频大概35分钟,训练久点效果更好
如果参考音频选择训练音频则推理出的声音更符合训练集音色,如果看看音频为非训练集音频,则为音频融合(音色融合),切分方式我感觉凑四句一切效果较好
还可以输入日文转英语,有那味了,
其他更多有待自己尝试了

评论