


sd插件
sd-webui-animatediff
https://github.com/continue-revolution/sd-webui-animatediff
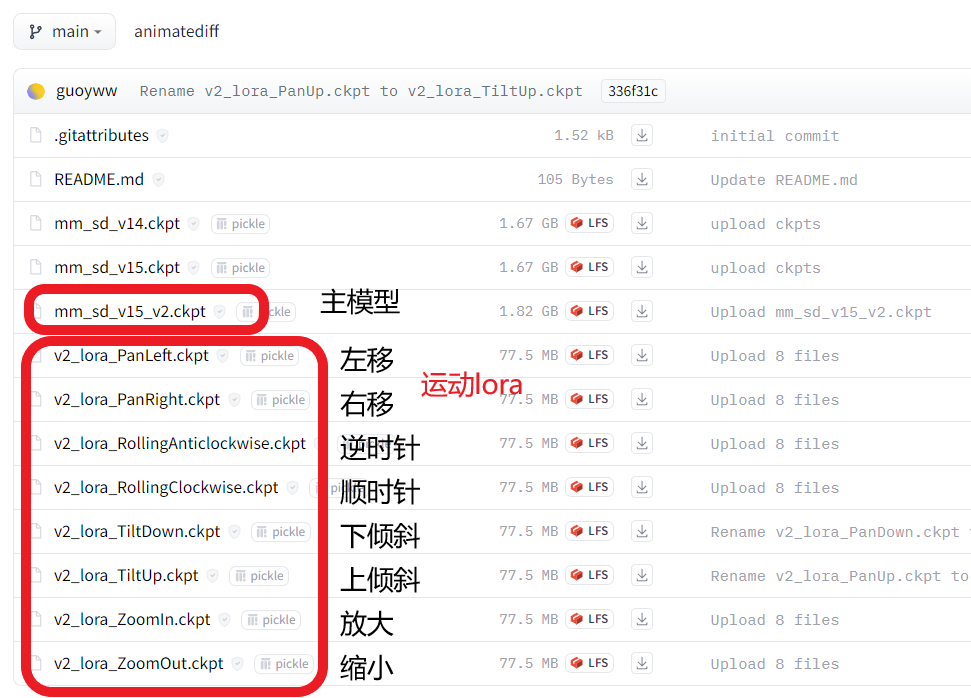
https://huggingface.co/guoyww/animatediff/tree/main
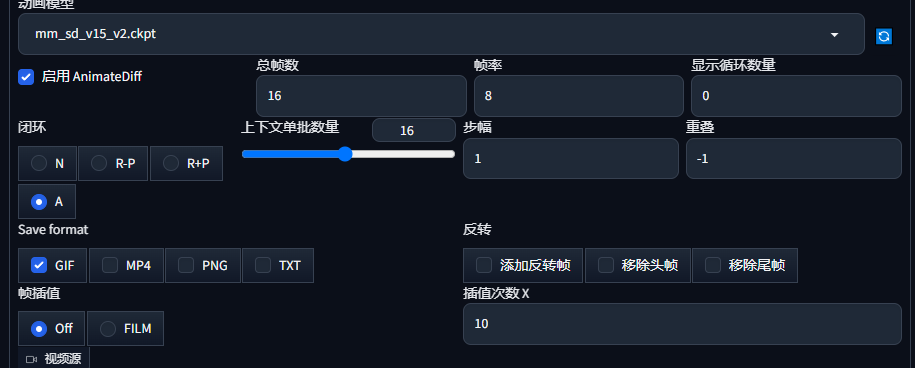
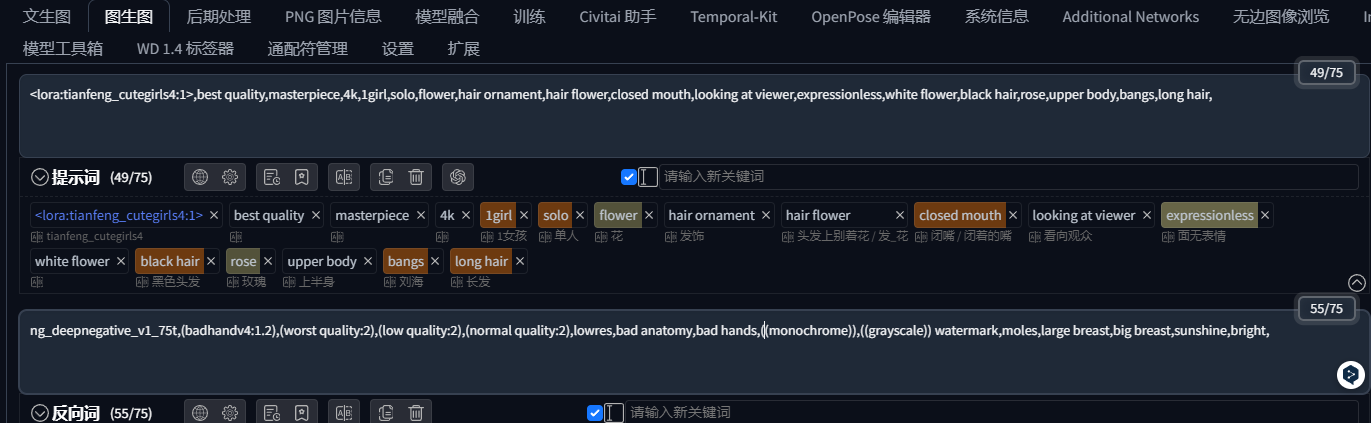
主模型放插件model路径,lora正常放置和使用,加点提示词,
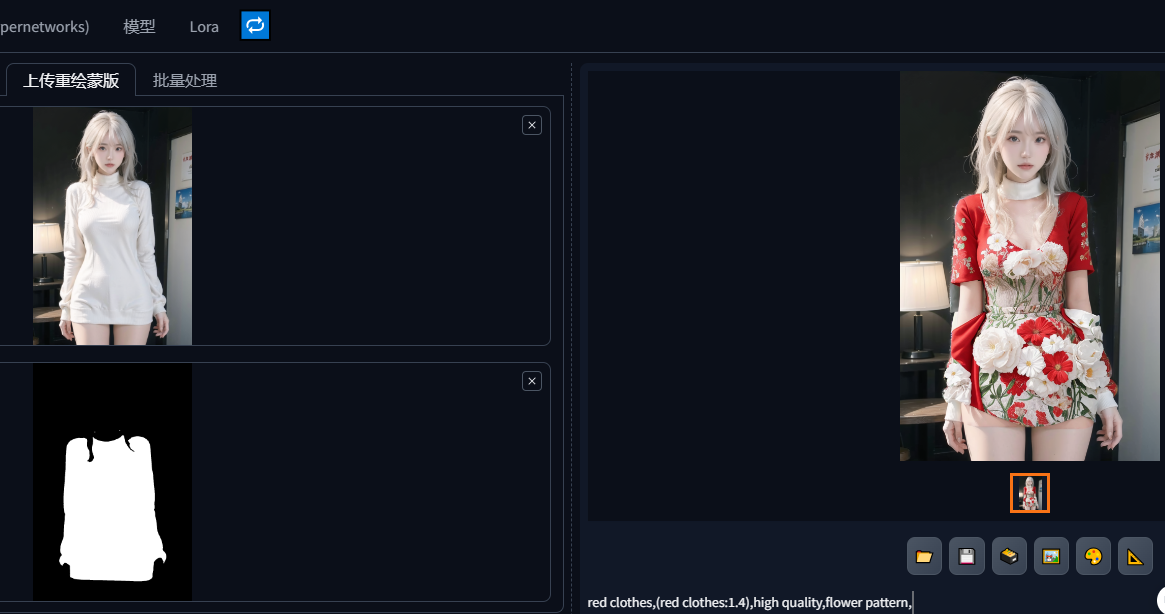
inpaint-anything
https://github.com/Uminosachi/sd-webui-inpaint-anything
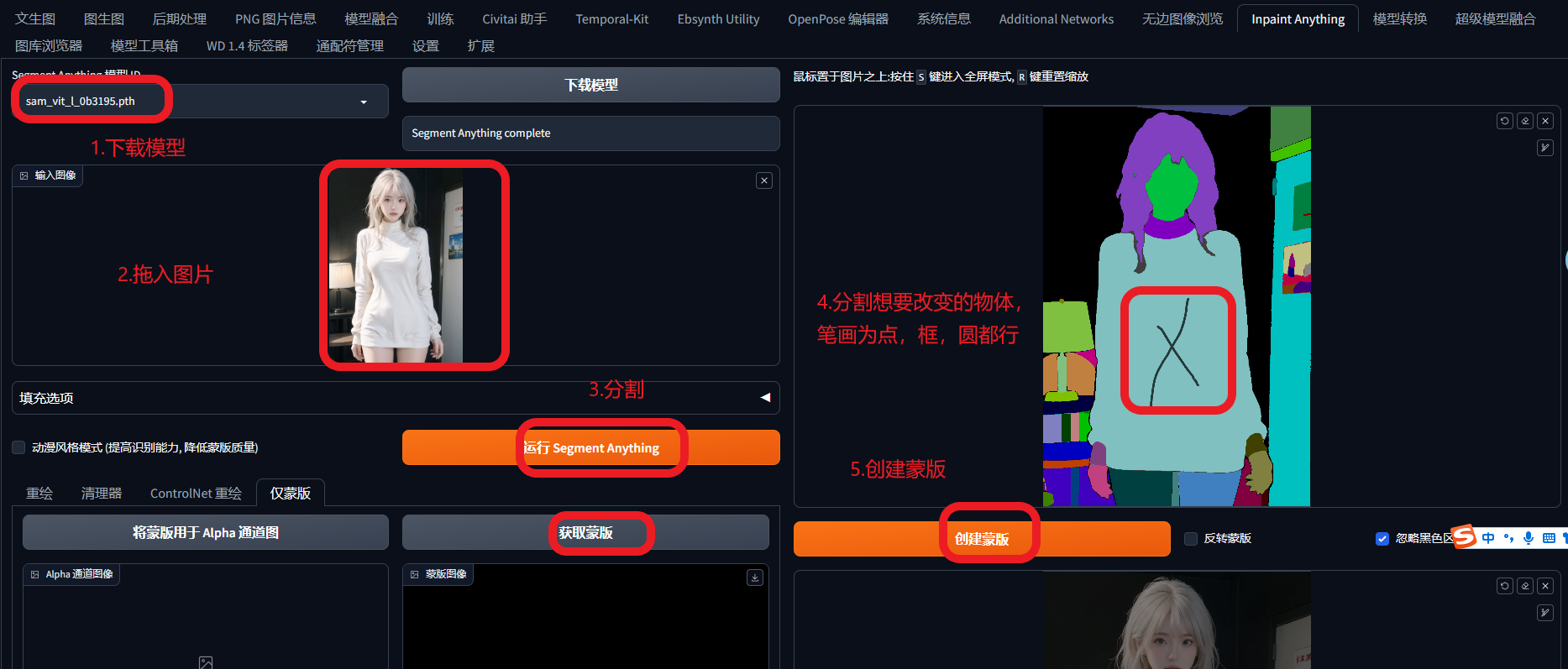
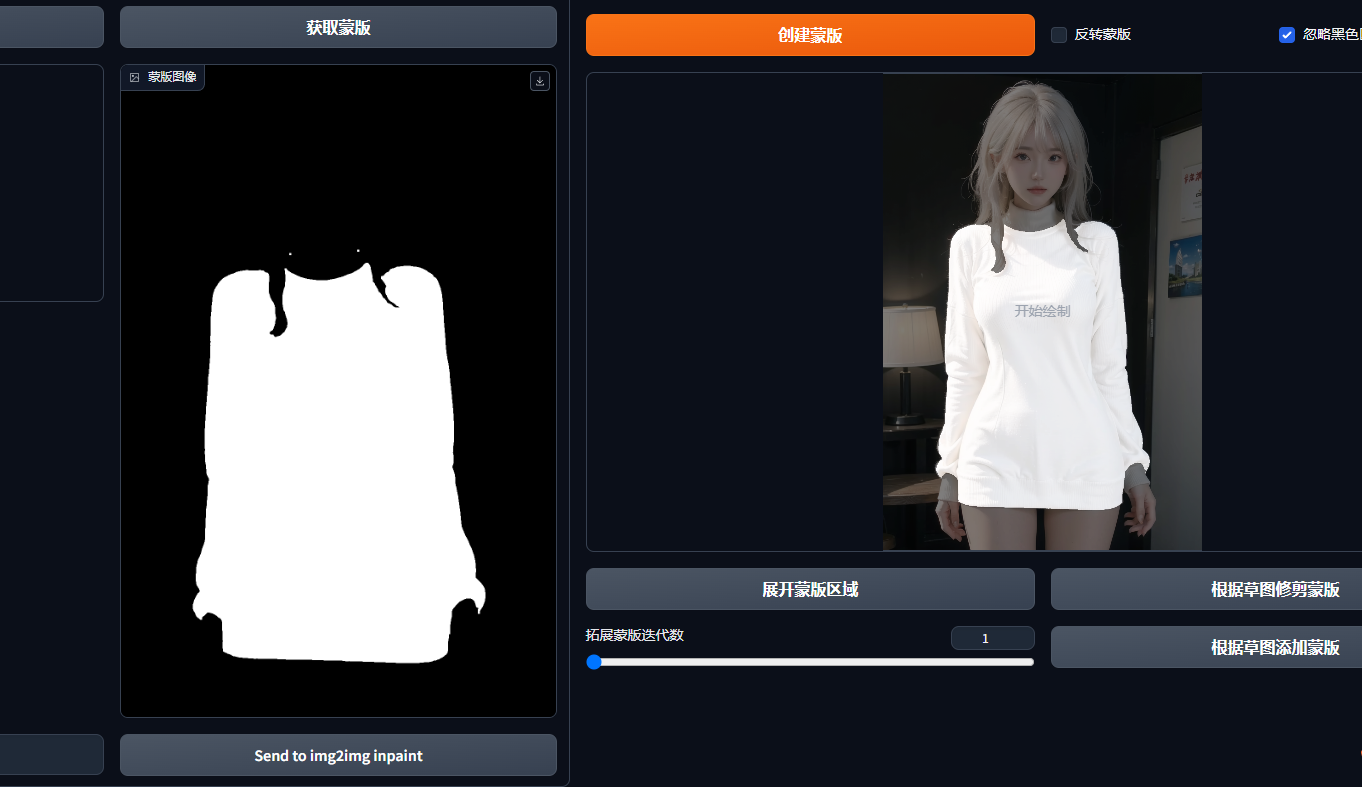
如果分割的物体,没问题,就点击获取蒙版,然后点击下面发送到图生图;简单写一点修改后的衣服提示词,如红色衣服,鲜花等
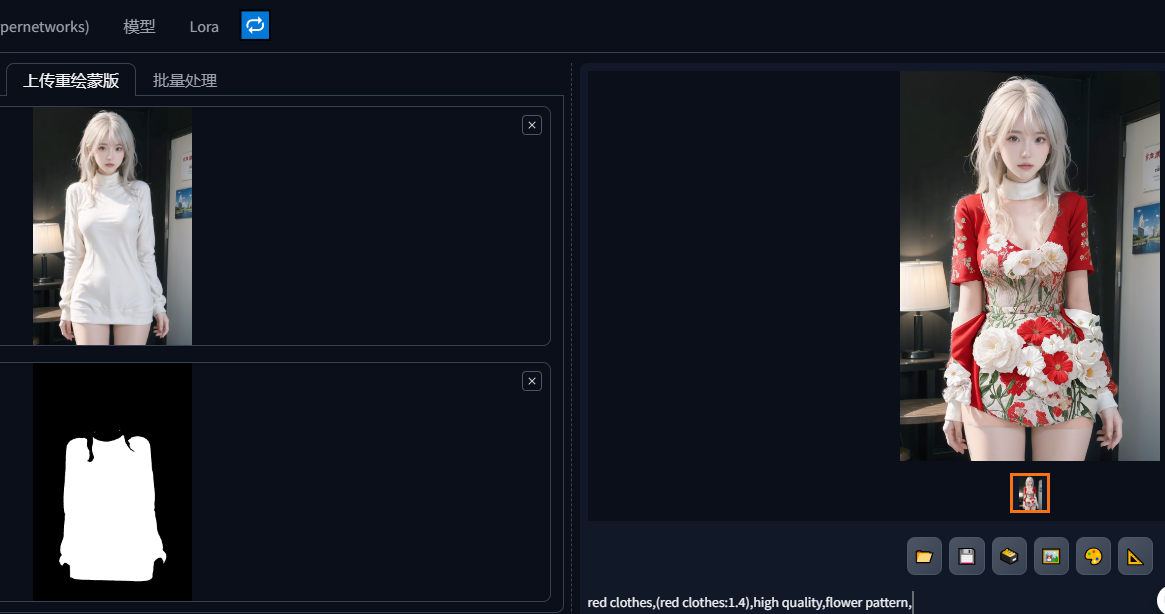
OK,换装完成!!!
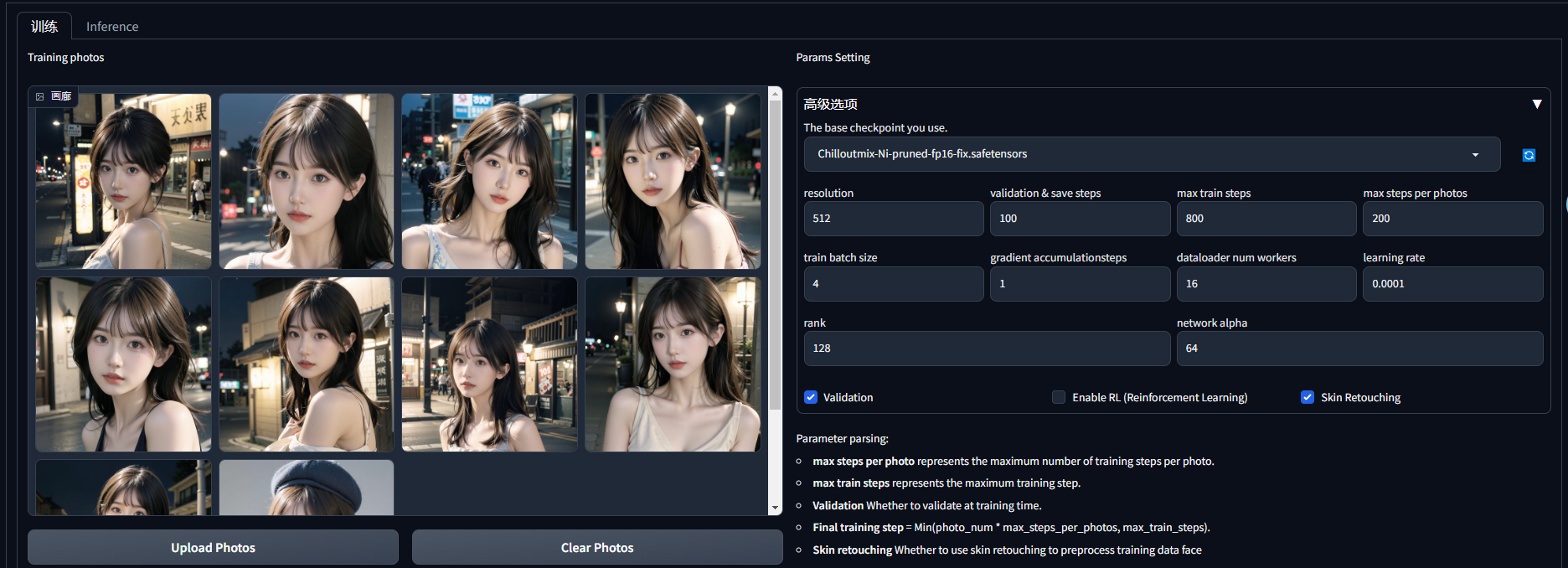
sd-webui-EasyPhoto
https://github.com/aigc-apps/sd-webui-EasyPhoto
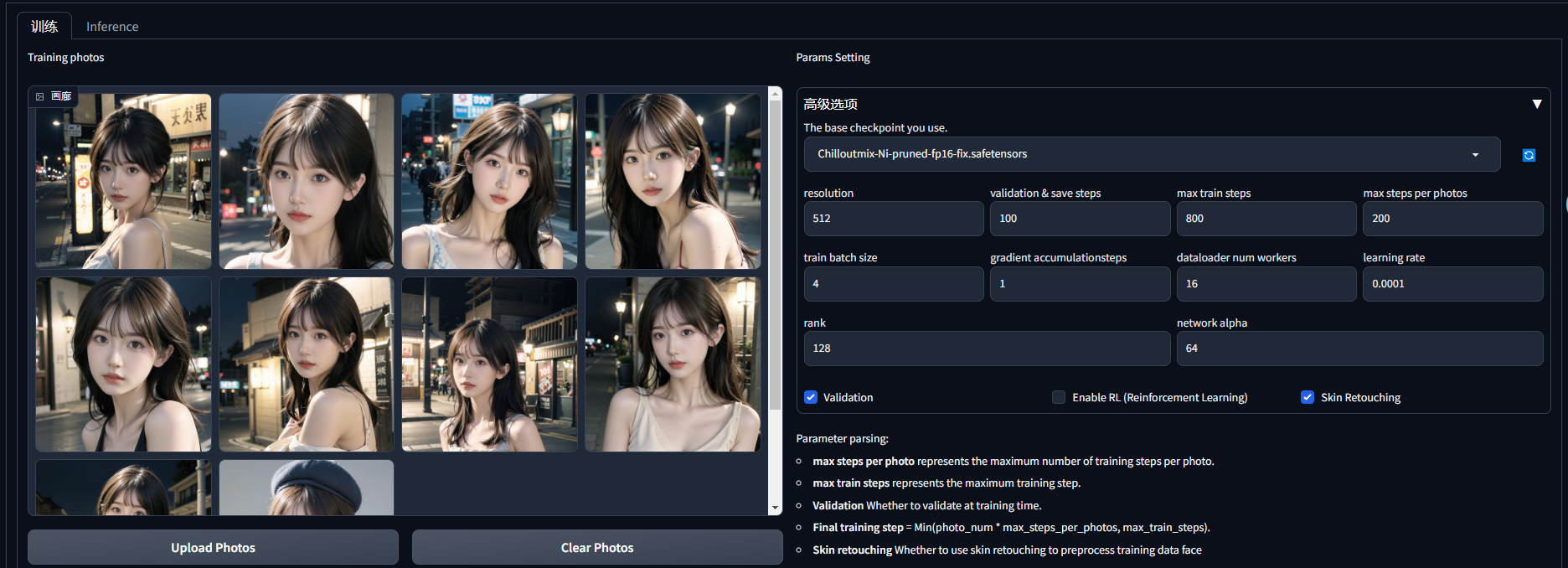
训练,上传10照片即可,参数基本不用动,batch size可以根据你的显存向上调整,对应梯度累加也要向下调整
推理
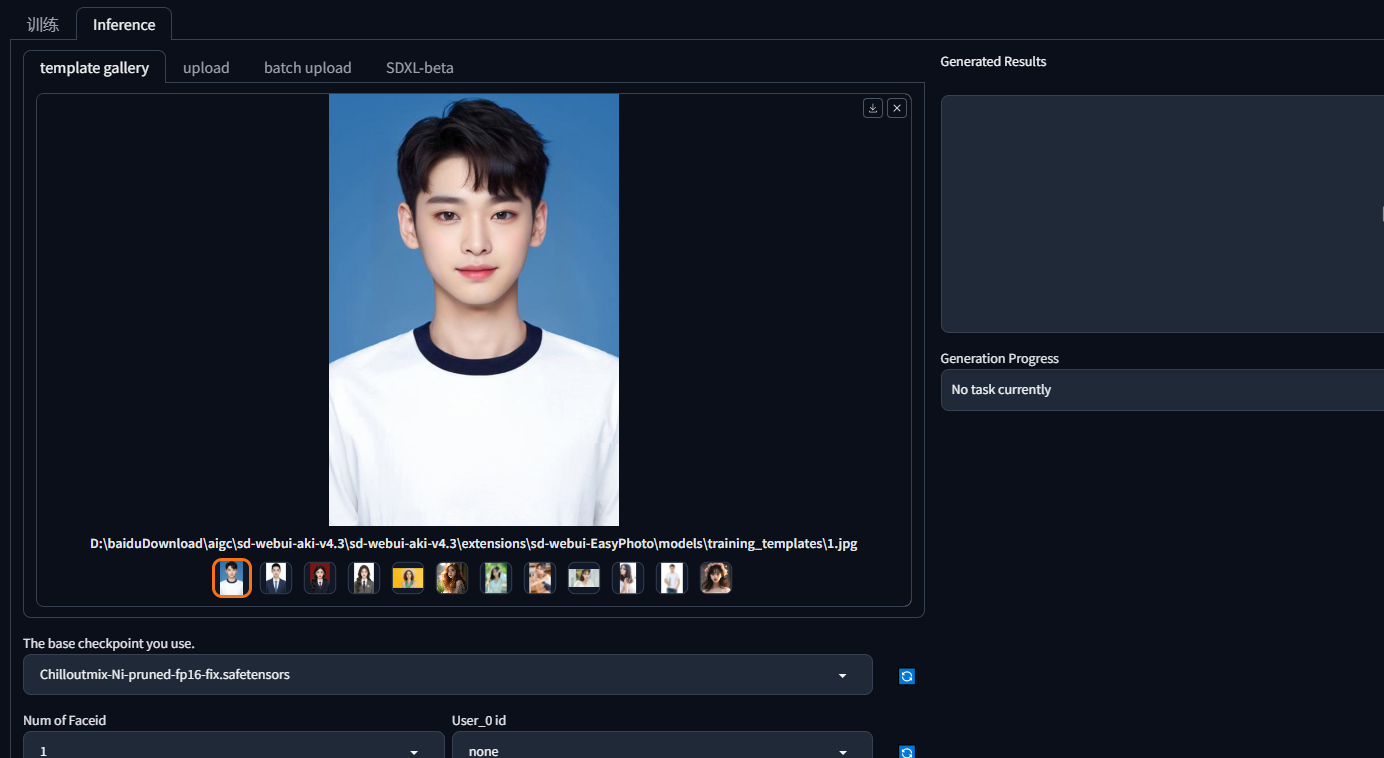
上面只是简单展示,具体可以看网站文档,写的挺详细
总结:个人感觉就是基于一些人脸肖像使用比较少的步数训练的lora,然后在图生图基础上用lora换脸,而且尺寸也不用太大,不过用在肖像上没啥问题;可以看着轻量级的换脸插件
图片扩充
如果你有一张文生图比较好的图片希望保存原图细节(或者其他来源图),进行横向扩充和纵向补充背景等,
提示词文生图的话直接复制过来,参数一样,其他则反推提示词
{kind=link}
{kind=link}
{kind=link}
原图1200x1200,重点你想怎么扩展,拉高分辨率即可
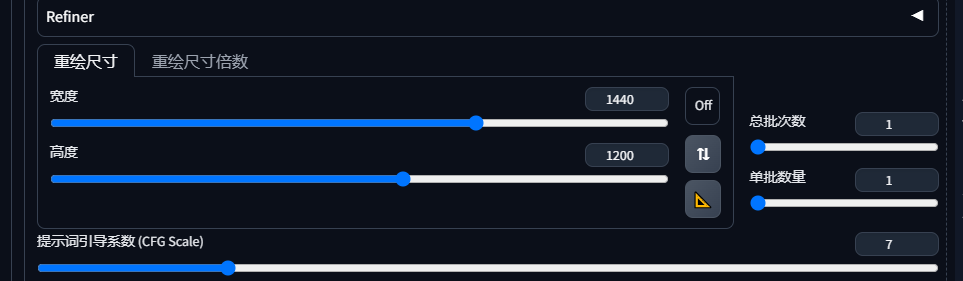

效果展示,只横向扩充200个像素
摄影级图片生成
https://liblib.ai/modelinfo/4d5083a6230343869c0e940b1d5e6329
1 girl, floral dress, long skirt like smoke, petal pattern, long hair in the wind, sense of luxury, stylish still photography, looping video, captivating movement, captivating visuals, seamless blend, fascinating story, swirls, edges Clear forms, dynamic movement, bold geometry, broken shapes, sharp contrasts, modernist influences, nature, history, modern art, stunning, unreal backgrounds, soft lighting, happy moods, (near distance, face focus) (fractal art) extremely detailed, the most beautiful forms chaos, elegance, with brutalist designs, vivid colors, immersion, details in the dark
推荐ai工具,有兴趣玩一下
https://convert.leiapix.com/animation
相关文章

我的公众号
微信扫一扫
评论