

前言
自此LCM公布以来,这一个星期在相关应用方面的更新速度nb,各种实时绘画工作流随之出现,之前还只能依赖krea内测资格使用,让我们来看看上周发生了那些事吧!
https://pan.quark.cn/s/223f12a85fa0
事件流程
本次讲解都是以comfyui为基础,如果没安装的可以看看,模型文件可以放在webui中,因为我的comfyui和webui共用一个模型文件夹
comfyui安装:https://blog.csdn.net/weixin_62403633/article/details/133994238?spm=1001.2014.3001.5501
LCM简单介绍:https://blog.csdn.net/weixin_62403633/article/details/134517970?spm=1001.2014.3001.5501
关于新手工作流搭建问题:可以先看看别人的,用的多了,相信你们自己后期也能搭建了
参考网站:https://comfyworkflows.com/
参考网站:https://civitai.com/search/models?sortBy=models_v5&query=workflow
参考网站:https://openart.ai/workflows/dev?sort=latest
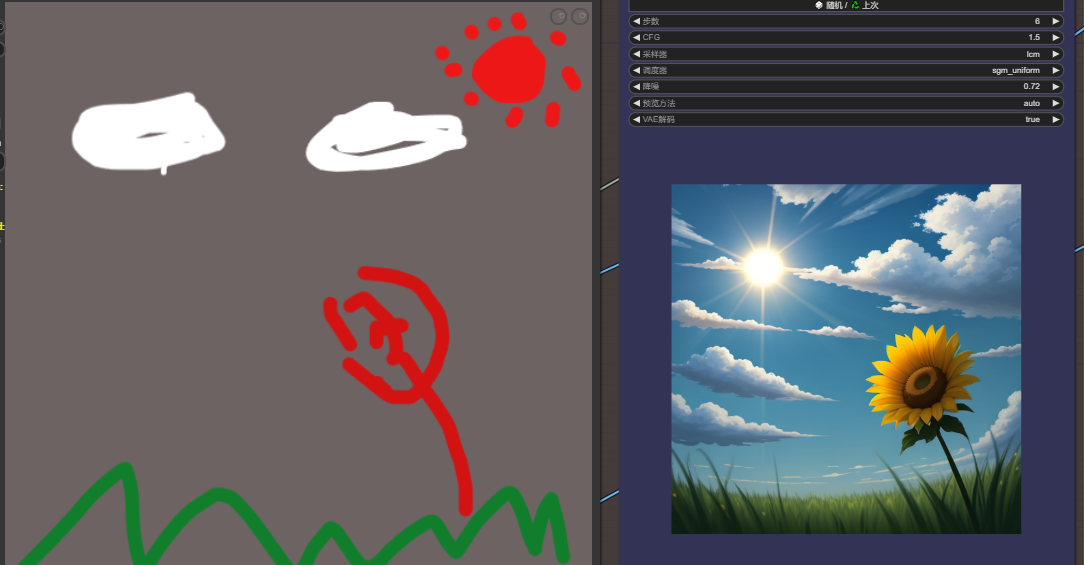
1.LCM实时绘画工作流
我先公布我的节点把,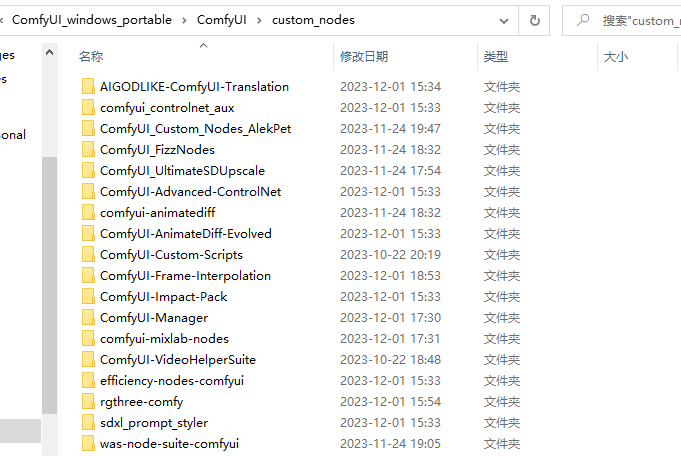
缺哪个安装,防止无法复现工作流,重启
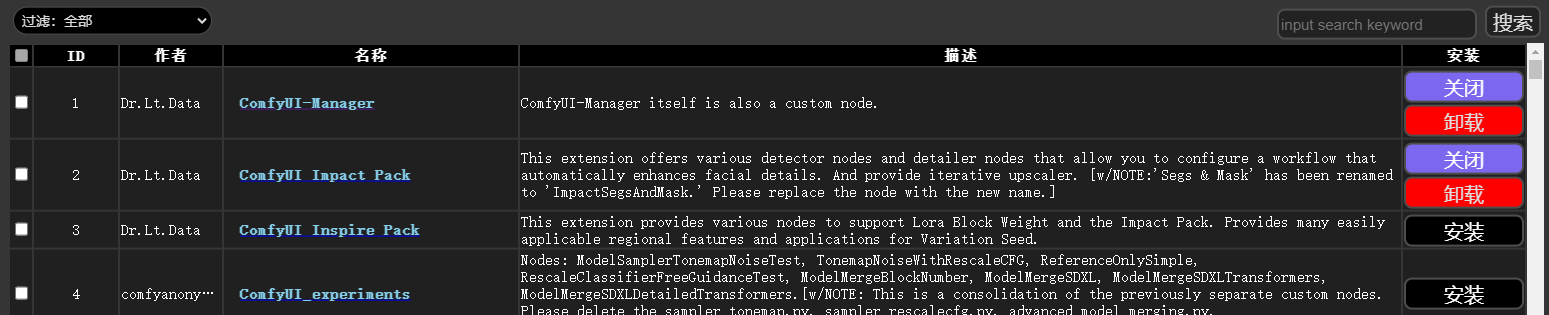
安装完毕记得全部更新一下
刚安装的这个也更新一下,两个脚本文件点击一下
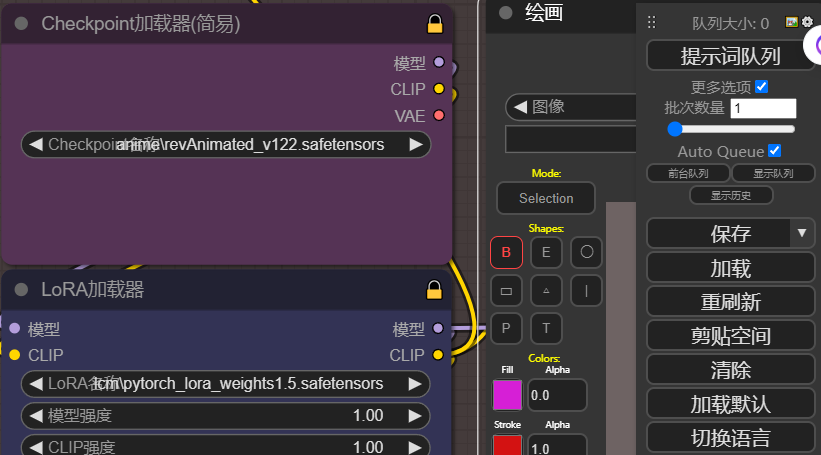
方案A:ComfyUI_Custom_Nodes_AlekPet节点(内置画板)
拖入工作流,ComfyUI_Custom_Nodes_AlekPet节点带有一个画板节点,可以直接画然后出结果,节点重新选一下模型和lcm-lora模型,右边勾选自动序列生成,点击提示词队列,开始实时绘画
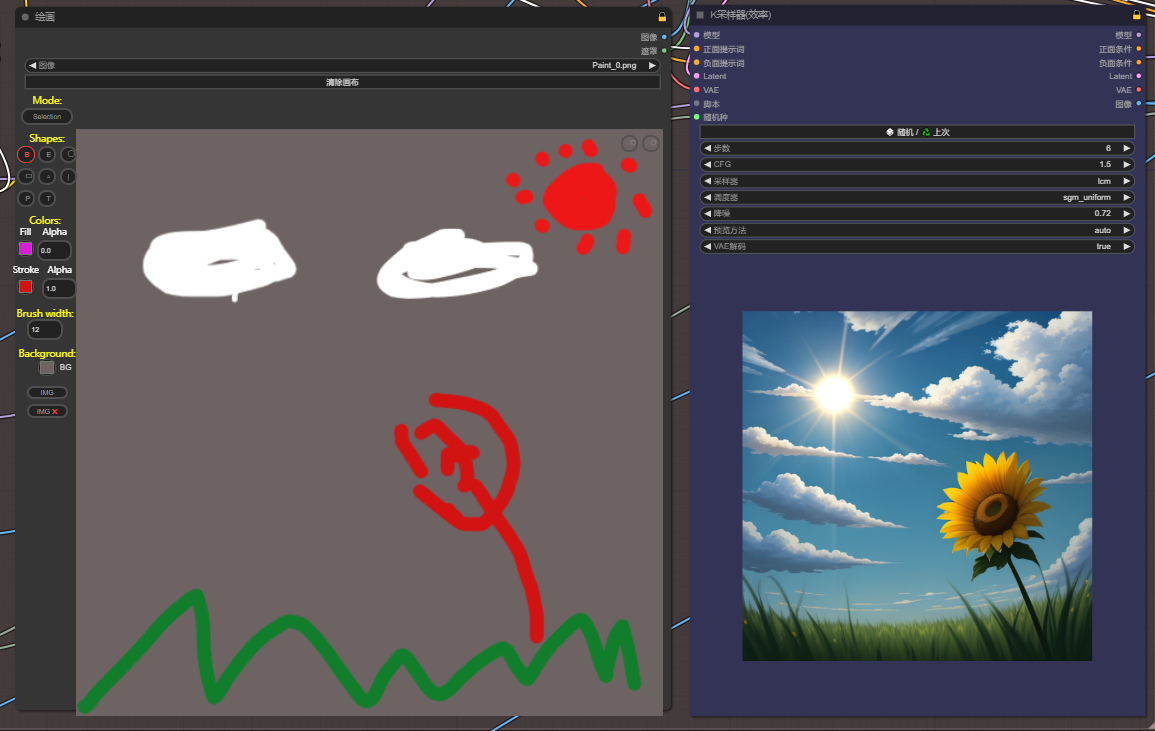
方案B:comfyui-mixlab-nodes节点(投屏)
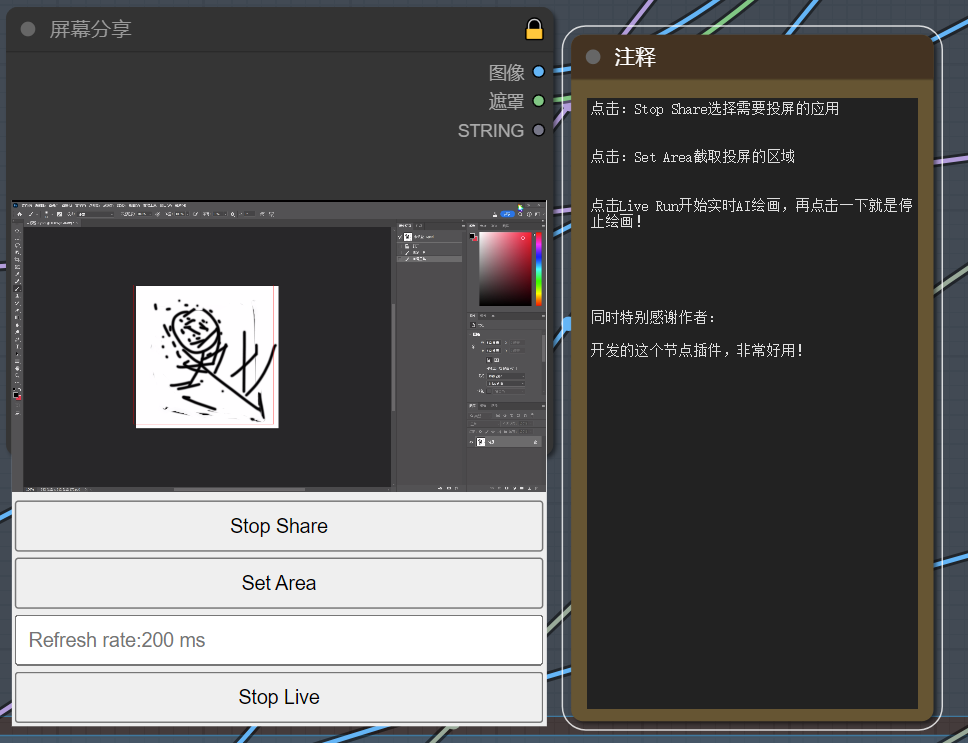
和上个工作流一样,就是画板节点换成了投屏节点
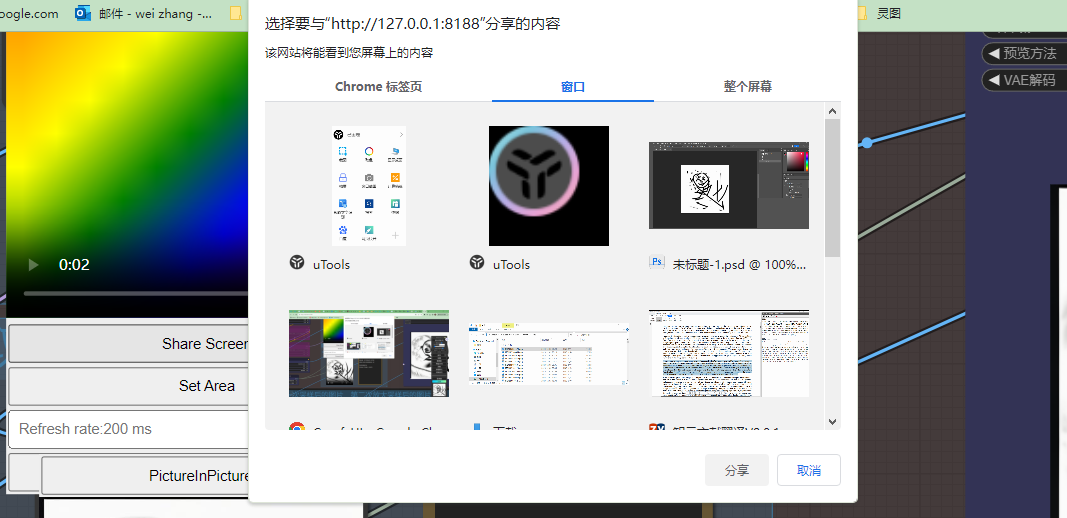
选择投屏ps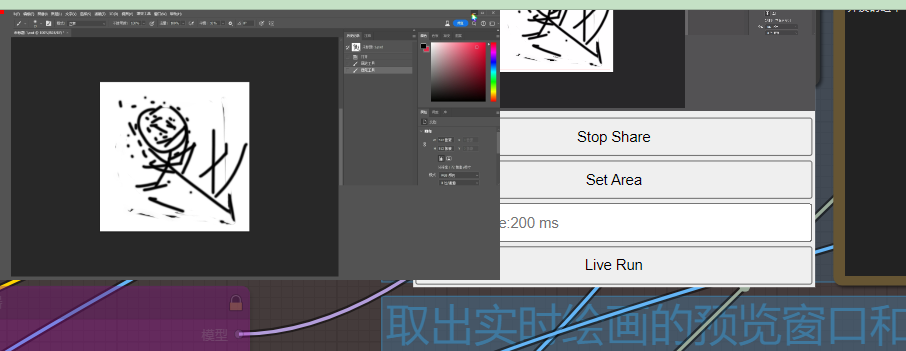
回到comfyui,矩形选择ps画板区域(左上角拉到右下角就行)
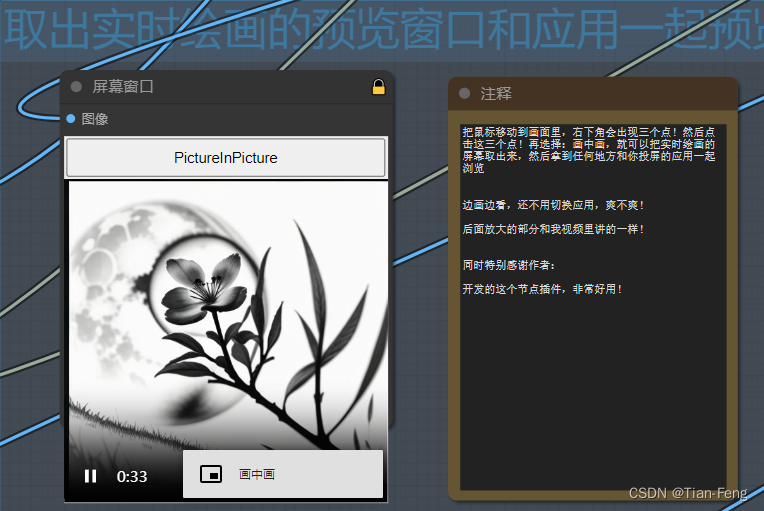
最后点击liveRun,开启画中画,comfyui点击提示词队列,就可以实时绘画了
假设投屏选择的是ps,这个时候就会根据ps绘画进行实时绘画,旁边就是画中画实时预览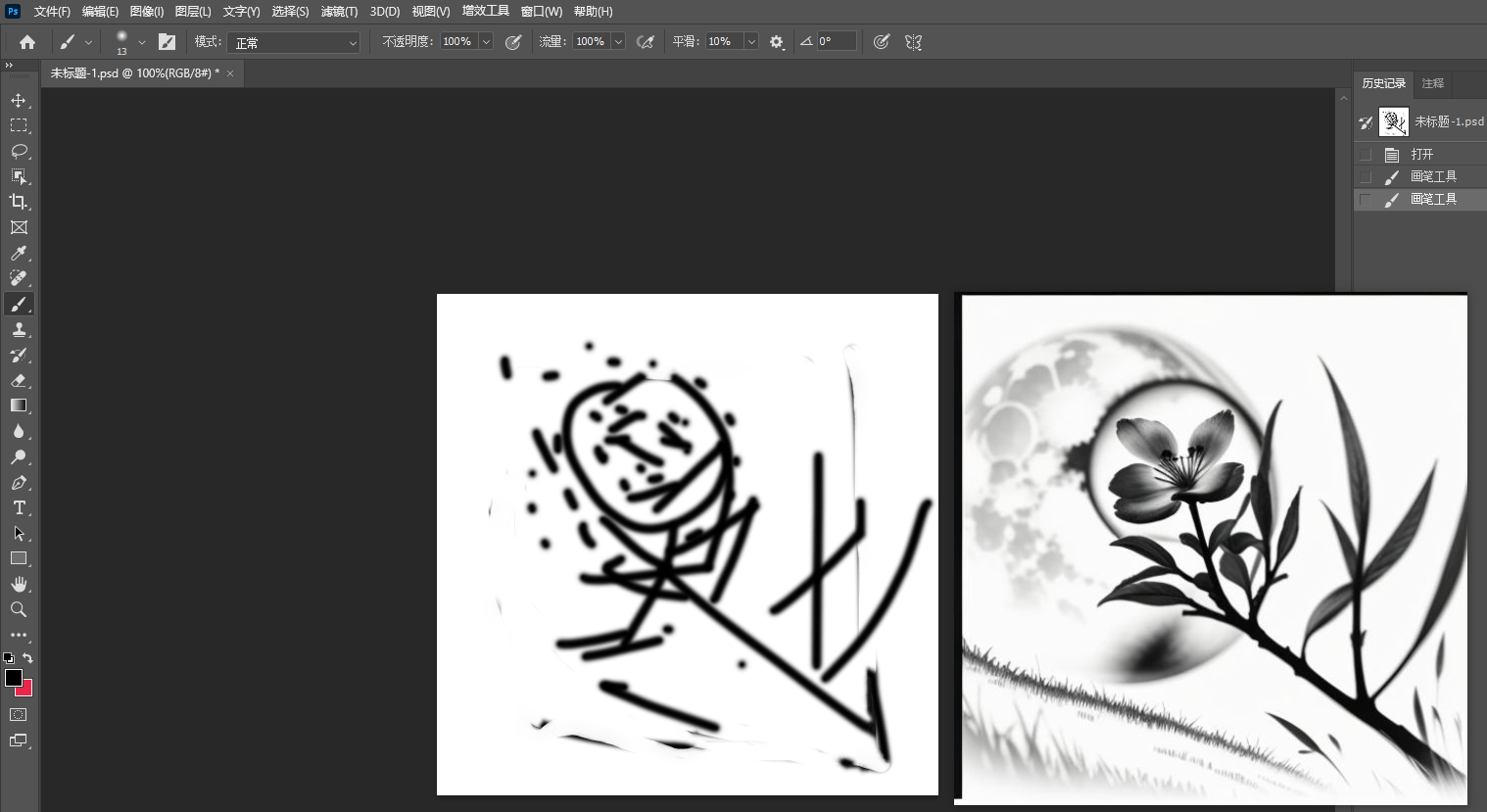
方案C:krita绘画工具结合comfyui
https://github.com/Acly/krita-ai-diffusion#installation

把应用和插件都下载了
https://github.com/Acly/krita-ai-diffusion/releases/download/v1.8.2/krita_ai_diffusion-1.8.2.zip
应用直接点击安装,打开后,把插件放在该目录下(插件如果更新下载替换就行)
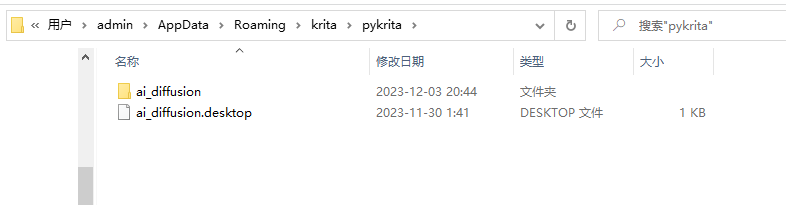
打开krita,设置选项中,配置krita中python插件管理勾选AI Image Diffusion重启
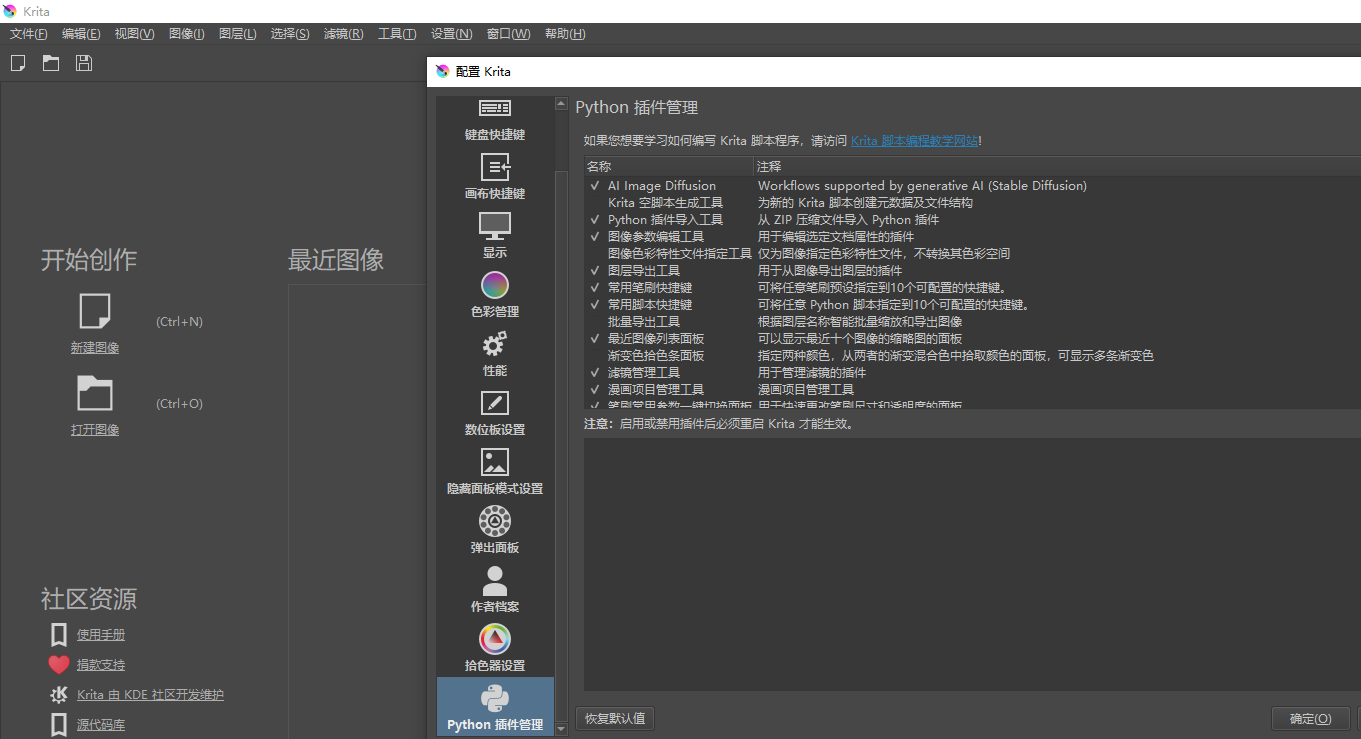
打开comfyui和krita,新建一个画布,一般根据模型sd1.5一般512x512,sdxl则1024x1024,创建完成右下角会出现如下图(如果没有,设置->面板列表->勾选AI Image Diffusion)
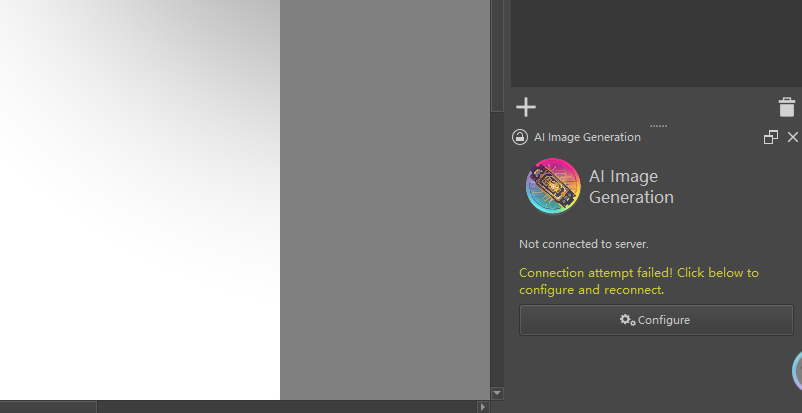
点击configure配置,红色是缺少节点,你可以直接点击下载解压放到comfyui节点目录下,也可以去comfyui搜索安装,如果没有git clone或者下载解压
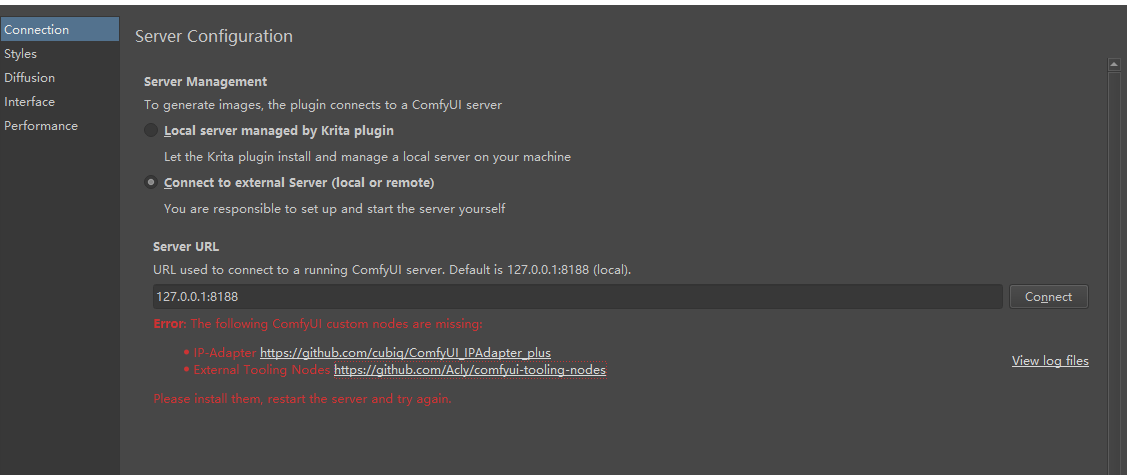
同时满足一下条件
https://github.com/Acly/krita-ai-diffusion/blob/main/doc/comfy-requirements.md

除了下载缺失节点还需要clip_vision模型放到models/clip_vision/SD1.5目录下
NMKD放大模型到models/upscale_models目录下
ipadapter模型放到custom_nodes/ComfyUI_IPAdapter_plus/models(直接把之前weui下的复制过去)
这个controlnet模型是放到节点里,所以共享模型无法识别;lcm-lora同样复制过来放了lora目录
(改名lcm-lora-sdv1-5.safetensors lcm-lora-sdxl.safetensors)
好了基本大功告成了,重新启动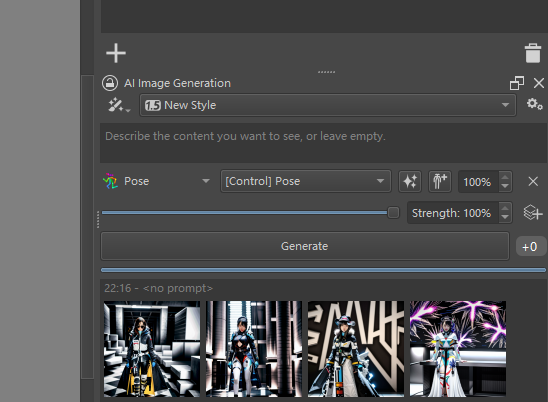
可以新建矢量图层,pose图,depth图等等,剩下的你们研究把!有问题私信。
2.SDXL-turbo
https://huggingface.co/stabilityai/sd-turbo/tree/main

SD-Turbo 是Stable Diffusion 2.1的精炼版本,经过实时合成训练。SD-Turbo 基于一种称为对抗扩散蒸馏 (ADD) 的新颖训练方法(请参阅技术报告),该方法允许在高图像质量下以 1 到 4 个步骤对大规模基础图像扩散模型进行采样。这种方法使用分数蒸馏来利用大规模现成的图像扩散模型作为教师信号,并将其与对抗性损失相结合,以确保即使在一个或两个采样步骤的低步骤状态下也能确保高图像保真度。
下载模型放置后搭建工作流体验,对物体还过得去,人物效果一般,期待后续优化。
提供两个工作流,可以https://civitai.com/models/219765/sdxl-turbo-lcmworkflow下载相应模型
2.SVD
SVD:该模型经过训练,可以在给定相同大小的上下文帧的情况下生成分辨率为 576x1024 的 14 帧。SVD-XT:与架构相同,SVD但针对 25 帧生成进行了微调。
SVD:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
SVD-XT:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt

当前局限性
-
生成的视频相当短(<= 4秒),并且该模型无法实现完美的照片级真实感。
-
该模型可能会生成没有运动或非常缓慢的摄像机平移的视频。
-
模型无法通过文本控制。
-
该模型无法呈现清晰的文本。
-
一般情况下,面孔和人物可能无法正确生成。
-
模型的自动编码部分是有损的。
下载对应模型文件即可使用,网盘提供一些工作流,更多请自己去我提供的网站下载吧!

评论