


一、朴素贝叶斯之新浪新闻分类(Sklearn)
1、语句切分
英文的语句可以通过非字母和非数字进行切分,但是汉语句子呢?就比如我打的这一堆字,该如何进行切分呢?我们自己写个规则?幸运地是,这部分的工作不需要我们自己做了,可以直接使用第三方分词组件,即jieba,jieba已经兼容Python2和Python3,使用如下指令直接安装即可:
pip3 install jieba
Python中文分词组件使用简单:
新闻分类数据集我也已经准备好,可以到我的Github进行下载:数据集下载
数据集已经做好分类,分文件夹保存,分类结果如下:

数据集已经准备好,接下来,让我们直接进入正题。切分中文语句,编写如下代码:
import os
import jieba
def TextProcessing(folder_path):
folder_list = os.listdir(folder_path) #查看folder_path下的文件
data_list = [] #训练集
class_list = []
#遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表
j = 1
#遍历每个txt文件
for file in files:
if j > 100: #每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件
raw = f.read()
word_cut = jieba.cut(raw, cut_all = False) #精简模式,返回一个可迭代的generator
word_list = list(word_cut) #generator转换为list
data_list.append(word_list)
class_list.append(folder)
j += 1
print(data_list)
print(class_list)
if __name__ == '__main__':
#文本预处理
folder_path = './SogouC/Sample' #训练集存放地址
TextProcessing(folder_path)
已经进行了切分,最下面输出了类别:
2、文本特征选择
我们将所有文本分成训练集和测试集,并对训练集中的所有单词进行词频统计,并按降序排序。也就是将出现次数多的词语在前,出现次数少的词语在后进行排序。编写代码如下:
import os
import random
import jieba
"""
函数说明:中文文本处理
Parameters:
folder_path - 文本存放的路径
test_size - 测试集占比,默认占所有数据集的百分之20
Returns:
all_words_list - 按词频降序排序的训练集列表
train_data_list - 训练集列表
test_data_list - 测试集列表
train_class_list - 训练集标签列表
test_class_list - 测试集标签列表
"""
def TextProcessing(folder_path, test_size = 0.2):
folder_list = os.listdir(folder_path) #查看folder_path下的文件
data_list = [] #数据集数据
class_list = [] #数据集类别
#遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表
j = 1
#遍历每个txt文件
for file in files:
if j > 100: #每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件
raw = f.read()
word_cut = jieba.cut(raw, cut_all = False) #精简模式,返回一个可迭代的generator
word_list = list(word_cut) #generator转换为list
data_list.append(word_list) #添加数据集数据
class_list.append(folder) #添加数据集类别
j += 1
data_class_list = list(zip(data_list, class_list)) #zip压缩合并,将数据与标签对应压缩
random.shuffle(data_class_list) #将data_class_list乱序
index = int(len(data_class_list) * test_size) + 1 #训练集和测试集切分的索引值
train_list = data_class_list[index:] #训练集
test_list = data_class_list[:index] #测试集
train_data_list, train_class_list = zip(*train_list) #训练集解压缩
test_data_list, test_class_list = zip(*test_list) #测试集解压缩
all_words_dict = {} #统计训练集词频
for word_list in train_data_list:
for word in word_list:
if word in all_words_dict.keys():
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
#根据键的值倒序排序
all_words_tuple_list = sorted(all_words_dict.items(), key = lambda f:f[1], reverse = True)
all_words_list, all_words_nums = zip(*all_words_tuple_list) #解压缩
all_words_list = list(all_words_list) #转换成列表
return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list
if __name__ == '__main__':
#文本预处理
folder_path = './SogouC/Sample' #训练集存放地址
all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2)
print(all_words_list)
我们需要把前面哪些标点符号删去,同时去除虽然但是这种词,怎么去除这些词呢?可以使用已经整理好的stopwords_cn.txt文本。下载地址:点我下载
我们可以根据这个文档,将这些单词去除,不作为分类的特征。我们先去除前100个高频词汇,然后编写代码如下:
import os
import random
import jieba
"""
函数说明:中文文本处理
Parameters:
folder_path - 文本存放的路径
test_size - 测试集占比,默认占所有数据集的百分之20
Returns:
all_words_list - 按词频降序排序的训练集列表
train_data_list - 训练集列表
test_data_list - 测试集列表
train_class_list - 训练集标签列表
test_class_list - 测试集标签列表
"""
def TextProcessing(folder_path, test_size = 0.2):
folder_list = os.listdir(folder_path) #查看folder_path下的文件
data_list = [] #数据集数据
class_list = [] #数据集类别
#遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表
j = 1
#遍历每个txt文件
for file in files:
if j > 100: #每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件
raw = f.read()
word_cut = jieba.cut(raw, cut_all = False) #精简模式,返回一个可迭代的generator
word_list = list(word_cut) #generator转换为list
data_list.append(word_list) #添加数据集数据
class_list.append(folder) #添加数据集类别
j += 1
data_class_list = list(zip(data_list, class_list)) #zip压缩合并,将数据与标签对应压缩
random.shuffle(data_class_list) #将data_class_list乱序
index = int(len(data_class_list) * test_size) + 1 #训练集和测试集切分的索引值
train_list = data_class_list[index:] #训练集
test_list = data_class_list[:index] #测试集
train_data_list, train_class_list = zip(*train_list) #训练集解压缩
test_data_list, test_class_list = zip(*test_list) #测试集解压缩
all_words_dict = {} #统计训练集词频
for word_list in train_data_list:
for word in word_list:
if word in all_words_dict.keys():
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
#根据键的值倒序排序
all_words_tuple_list = sorted(all_words_dict.items(), key = lambda f:f[1], reverse = True)
all_words_list, all_words_nums = zip(*all_words_tuple_list) #解压缩
all_words_list = list(all_words_list) #转换成列表
return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list
"""
函数说明:读取文件里的内容,并去重
Parameters:
words_file - 文件路径
Returns:
words_set - 读取的内容的set集合
"""
def MakeWordsSet(words_file):
words_set = set() #创建set集合
with open(words_file, 'r', encoding = 'utf-8') as f: #打开文件
for line in f.readlines(): #一行一行读取
word = line.strip() #去回车
if len(word) > 0: #有文本,则添加到words_set中
words_set.add(word)
return words_set #返回处理结果
"""
函数说明:文本特征选取
Parameters:
all_words_list - 训练集所有文本列表
deleteN - 删除词频最高的deleteN个词
stopwords_set - 指定的结束语
Returns:
feature_words - 特征集
"""
def words_dict(all_words_list, deleteN, stopwords_set = set()):
feature_words = [] #特征列表
n = 1
for t in range(deleteN, len(all_words_list), 1):
if n > 1000: #feature_words的维度为1000
break
#如果这个词不是数字,并且不是指定的结束语,并且单词长度大于1小于5,那么这个词就可以作为特征词
if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:
feature_words.append(all_words_list[t])
n += 1
return feature_words
if __name__ == '__main__':
#文本预处理
folder_path = './SogouC/Sample' #训练集存放地址
all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2)
#生成stopwords_set
stopwords_file = './stopwords_cn.txt'
stopwords_set = MakeWordsSet(stopwords_file)
feature_words = words_dict(all_words_list, 100, stopwords_set)
print(feature_words)

可以看到,我们已经滤除了那些没有用的词组,这个feature_words就是我们最终选出的用于新闻分类的特征。随后,我们就可以根据feature_words,将文本向量化,然后用于训练朴素贝叶斯分类器。
3、使用Sklearn构建朴素贝叶斯分类器
数据已经处理好了,接下来就可以使用sklearn构建朴素贝叶斯分类器了。
官方英文文档地址:文档地址
朴素贝叶斯是一类比较简单的算法,scikit-learn中朴素贝叶斯类库的使用也比较简单。相对于决策树,KNN之类的算法,朴素贝叶斯需要关注的参数是比较少的,这样也比较容易掌握。在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。分别是GaussianNB,MultinomialNB和BernoulliNB。其中GaussianNB就是先验为高斯分布的朴素贝叶斯,MultinomialNB就是先验为多项式分布的朴素贝叶斯,而BernoulliNB就是先验为伯努利分布的朴素贝叶斯。上篇文章讲解的先验概率模型就是先验概率为多项式分布的朴素贝叶斯。

对于新闻分类,属于多分类问题。我们可以使用MultinamialNB()完成我们的新闻分类问题。另外两个函数的使用暂且不再进行扩展,可以自行学习。MultinomialNB假设特征的先验概率为多项式分布,即如下式:

其中, P(Xj = Xjl | Y = Ck)是第k个类别的第j维特征的第l个取值条件概率。mk是训练集中输出为第k类的样本个数。λ为一个大于0的常数,常常取值为1,即拉普拉斯平滑,也可以取其他值。
接下来,我们看下MultinamialNB这个函数,只有3个参数:
参数说明如下:
- alpha:浮点型可选参数,默认为1.0,其实就是添加拉普拉斯平滑,即为上述公式中的λ ,如果这个参数设置为0,就是不添加平滑;
- fit_prior:布尔型可选参数,默认为True。布尔参数fit_prior表示是否要考虑先验概率,如果是false,则所有的样本类别输出都有相同的类别先验概率。否则可以自己用第三个参数class_prior输入先验概率,或者不输入第三个参数class_prior让MultinomialNB自己从训练集样本来计算先验概率,此时的先验概率为P(Y=Ck)=mk/m。其中m为训练集样本总数量,mk为输出为第k类别的训练集样本数。
- class_prior:可选参数,默认为None。
总结如下:

除此之外,MultinamialNB也有一些方法供我们使用:
Methods
fit(X, y[, sample_weight]) |
根据X,y拟合Naive Bayes分类器 |
|---|---|
get_params([deep]) |
获取此估计器的参数 |
partial_fit(X, y[, classes, sample_weight]) |
批量样品的增量拟合 |
predict(X) |
对测试向量X的数组执行分类 |
predict_joint_log_proba(X) |
返回测试向量X的联合对数概率估计 |
predict_log_proba(X) |
测试向量X的返回对数概率估计 |
predict_proba |
测试向量X的返回概率估计 |
score(X, y[, sample_weight]) |
返回给定测试数据和标签的平均精度 |
set_params(**params) |
设置此估计器的参数 |
MultinomialNB一个重要的功能是有partial_fit方法,这个方法的一般用在如果训练集数据量非常大,一次不能全部载入内存的时候。这时我们可以把训练集分成若干等分,重复调用partial_fit来一步步的学习训练集,非常方便。GaussianNB和BernoulliNB也有类似的功能。 在使用MultinomialNB的fit方法或者partial_fit方法拟合数据后,我们可以进行预测。此时预测有三种方法,包括predict,predict_log_proba和predict_proba。predict方法就是我们最常用的预测方法,直接给出测试集的预测类别输出。predict_proba则不同,它会给出测试集样本在各个类别上预测的概率。容易理解,predict_proba预测出的各个类别概率里的最大值对应的类别,也就是predict方法得到类别。predict_log_proba和predict_proba类似,它会给出测试集样本在各个类别上预测的概率的一个对数转化。转化后predict_log_proba预测出的各个类别对数概率里的最大值对应的类别,也就是predict方法得到类别。具体细节不再讲解,可参照官网手册。
了解了这些,我们就可以编写代码,通过观察取不同的去掉前deleteN个高频词的个数与最终检测准确率的关系,确定deleteN的取值:
from sklearn.naive_bayes import MultinomialNB
import matplotlib.pyplot as plt
import os
import random
import jieba
"""
函数说明:中文文本处理
Parameters:
folder_path - 文本存放的路径
test_size - 测试集占比,默认占所有数据集的百分之20
Returns:
all_words_list - 按词频降序排序的训练集列表
train_data_list - 训练集列表
test_data_list - 测试集列表
train_class_list - 训练集标签列表
test_class_list - 测试集标签列表
"""
def TextProcessing(folder_path, test_size = 0.2):
folder_list = os.listdir(folder_path) #查看folder_path下的文件
data_list = [] #数据集数据
class_list = [] #数据集类别
#遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表
j = 1
#遍历每个txt文件
for file in files:
if j > 100: #每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件
raw = f.read()
word_cut = jieba.cut(raw, cut_all = False) #精简模式,返回一个可迭代的generator
word_list = list(word_cut) #generator转换为list
data_list.append(word_list) #添加数据集数据
class_list.append(folder) #添加数据集类别
j += 1
data_class_list = list(zip(data_list, class_list)) #zip压缩合并,将数据与标签对应压缩
random.shuffle(data_class_list) #将data_class_list乱序
index = int(len(data_class_list) * test_size) + 1 #训练集和测试集切分的索引值
train_list = data_class_list[index:] #训练集
test_list = data_class_list[:index] #测试集
train_data_list, train_class_list = zip(*train_list) #训练集解压缩
test_data_list, test_class_list = zip(*test_list) #测试集解压缩
all_words_dict = {} #统计训练集词频
for word_list in train_data_list:
for word in word_list:
if word in all_words_dict.keys():
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
#根据键的值倒序排序
all_words_tuple_list = sorted(all_words_dict.items(), key = lambda f:f[1], reverse = True)
all_words_list, all_words_nums = zip(*all_words_tuple_list) #解压缩
all_words_list = list(all_words_list) #转换成列表
return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list
"""
函数说明:读取文件里的内容,并去重
Parameters:
words_file - 文件路径
Returns:
words_set - 读取的内容的set集合
"""
def MakeWordsSet(words_file):
words_set = set() #创建set集合
with open(words_file, 'r', encoding = 'utf-8') as f: #打开文件
for line in f.readlines(): #一行一行读取
word = line.strip() #去回车
if len(word) > 0: #有文本,则添加到words_set中
words_set.add(word)
return words_set #返回处理结果
"""
函数说明:根据feature_words将文本向量化
Parameters:
train_data_list - 训练集
test_data_list - 测试集
feature_words - 特征集
Returns:
train_feature_list - 训练集向量化列表
test_feature_list - 测试集向量化列表
"""
def TextFeatures(train_data_list, test_data_list, feature_words):
def text_features(text, feature_words): #出现在特征集中,则置1
text_words = set(text)
features = [1 if word in text_words else 0 for word in feature_words]
return features
train_feature_list = [text_features(text, feature_words) for text in train_data_list]
test_feature_list = [text_features(text, feature_words) for text in test_data_list]
return train_feature_list, test_feature_list #返回结果
"""
函数说明:文本特征选取
Parameters:
all_words_list - 训练集所有文本列表
deleteN - 删除词频最高的deleteN个词
stopwords_set - 指定的结束语
Returns:
feature_words - 特征集
"""
def words_dict(all_words_list, deleteN, stopwords_set = set()):
feature_words = [] #特征列表
n = 1
for t in range(deleteN, len(all_words_list), 1):
if n > 1000: #feature_words的维度为1000
break
#如果这个词不是数字,并且不是指定的结束语,并且单词长度大于1小于5,那么这个词就可以作为特征词
if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:
feature_words.append(all_words_list[t])
n += 1
return feature_words
"""
函数说明:新闻分类器
Parameters:
train_feature_list - 训练集向量化的特征文本
test_feature_list - 测试集向量化的特征文本
train_class_list - 训练集分类标签
test_class_list - 测试集分类标签
Returns:
test_accuracy - 分类器精度
"""
def TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list):
classifier = MultinomialNB().fit(train_feature_list, train_class_list)
test_accuracy = classifier.score(test_feature_list, test_class_list)
return test_accuracy
if __name__ == '__main__':
#文本预处理
folder_path = './SogouC/Sample' #训练集存放地址
all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2)
# 生成stopwords_set
stopwords_file = './stopwords_cn.txt'
stopwords_set = MakeWordsSet(stopwords_file)
test_accuracy_list = []
deleteNs = range(0, 1000, 20) #0 20 40 60 ... 980
for deleteN in deleteNs:
feature_words = words_dict(all_words_list, deleteN, stopwords_set)
train_feature_list, test_feature_list = TextFeatures(train_data_list, test_data_list, feature_words)
test_accuracy = TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list)
test_accuracy_list.append(test_accuracy)
plt.figure()
plt.plot(deleteNs, test_accuracy_list)
plt.title('Relationship of deleteNs and test_accuracy')
plt.xlabel('deleteNs')
plt.ylabel('test_accuracy')
plt.show()
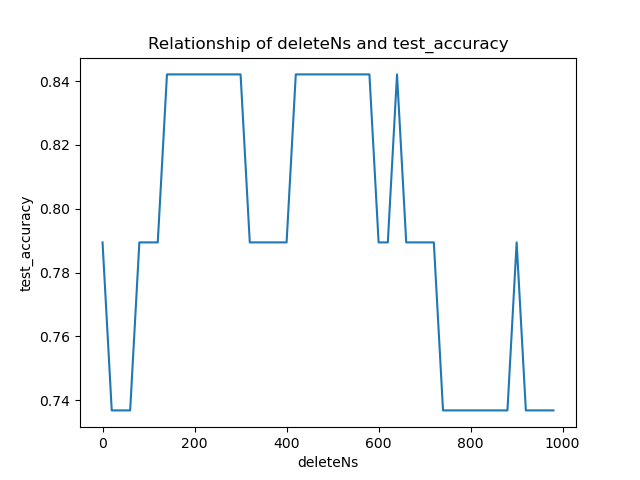
选择450输出,试试精确度。
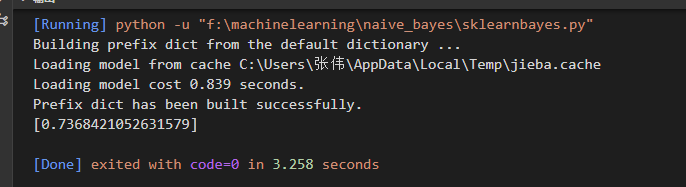
if __name__ == '__main__': #文本预处理 folder_path = 'F:\machinelearning\\naive_bayes\SogouC\Sample' #训练集存放地址 all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2) stopwords_file = 'F:\machinelearning\\naive_bayes\stopwords_cn.txt' stopwords_set = MakeWordsSet(stopwords_file) test_accuracy_list = [] feature_words = words_dict(all_words_list, 450, stopwords_set) train_feature_list, test_feature_list = TextFeatures(train_data_list, test_data_list, feature_words) test_accuracy = TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list) test_accuracy_list.append(test_accuracy) #ave = lambda c: sum(c) / len(c) #print(ave(test_accuracy_list)) print(test_accuracy_list)
4 本章小结
对于分类而言,使用概率有时要比使用硬规则更为有效。贝叶斯概率及贝叶斯准则提供了一种利用已知值来估计未知概率的有效方法。可以通过特征之间的条件独立性假设,降低对数据量的需求。独立性假设是指一个词的出现概率并不依赖于文档中的其他词。当然我们也知道这个假设过于简单。这就是之所以称为朴素贝叶斯的原因。尽管条件独立性假设并不正确,但是朴素贝叶斯仍然是一种有效的分类器。利用现代编程语言来实现朴素贝叶斯时需要考虑很多实际因素。下溢出就是其中一个问题,它可以通过对概率取对数来解决。词袋模型在解决文档分类问题上比词集模型有所提高。还有其他一些方面的改进,比如说移除停用词,当然也可以花大量时间对切分器进行优化。
参考资料:
- 本文的代码部分参考机器学习实战
- 本文的理论部分,参考自《统计学习方法 李航》

评论