


一、前言
Yolov5是一种基于深度学习的目标检测算法,它可以在图像或视频中实现实时目标检测。它是YOLO(You Only Look Once)系列算法的最新版本,相比之前的版本,它具有更高的检测精度和更快的检测速度。相比于YOLOv4,YOLOv5的改进主要有以下几点:
- 更高的检测精度:YOLOv5采用了更深的模型结构和更多的特征层,可以提高目标检测的精度。
- 更快的检测速度:YOLOv5采用了更轻量化的模型结构和更高效的计算方式,可以在保持精度的同时提高检测速度。
- 更好的通用性:YOLOv5在训练数据上进行了优化,可以适应更广泛的场景和物体类别。
- 更方便的训练和部署:YOLOv5提供了更友好的API和更简单的部署方式
YOLOv5是一个开源项目,在GitHub上免费提供。代码方面比YOLOV3看起来好太多了,非常的简洁精炼,作者功底之深可见一斑,YOLOV4可以认为理论方面,V5实践方面。作者没有发表论文。代码
二、YOLO-V5模型
1.概述
YOLOv5在模块方面并没有多太多东西,加了CSP模块,还有各个版本的激活函数并不是一样的,V5的第三代是hardwish,前面是Leaky ReLU,第四代是wish,上一篇文章提过,反正无论什么激活函数目的都一样,自己搜一下,跟relu差不多,就是负数部分做了调整。
模块可以先看完V4,V4上没有的我会加上去。
2.新增模块
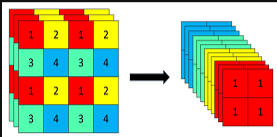
- Focus模块:先分块,后拼接,再卷积,间隔的来完成分块任务,此时卷积输入的C就为12了,参考实验结果并不多,目的是为了加速,并不会增加AP
- 激活函数,不同版本都不一样,注意一下就行
3.整体框架
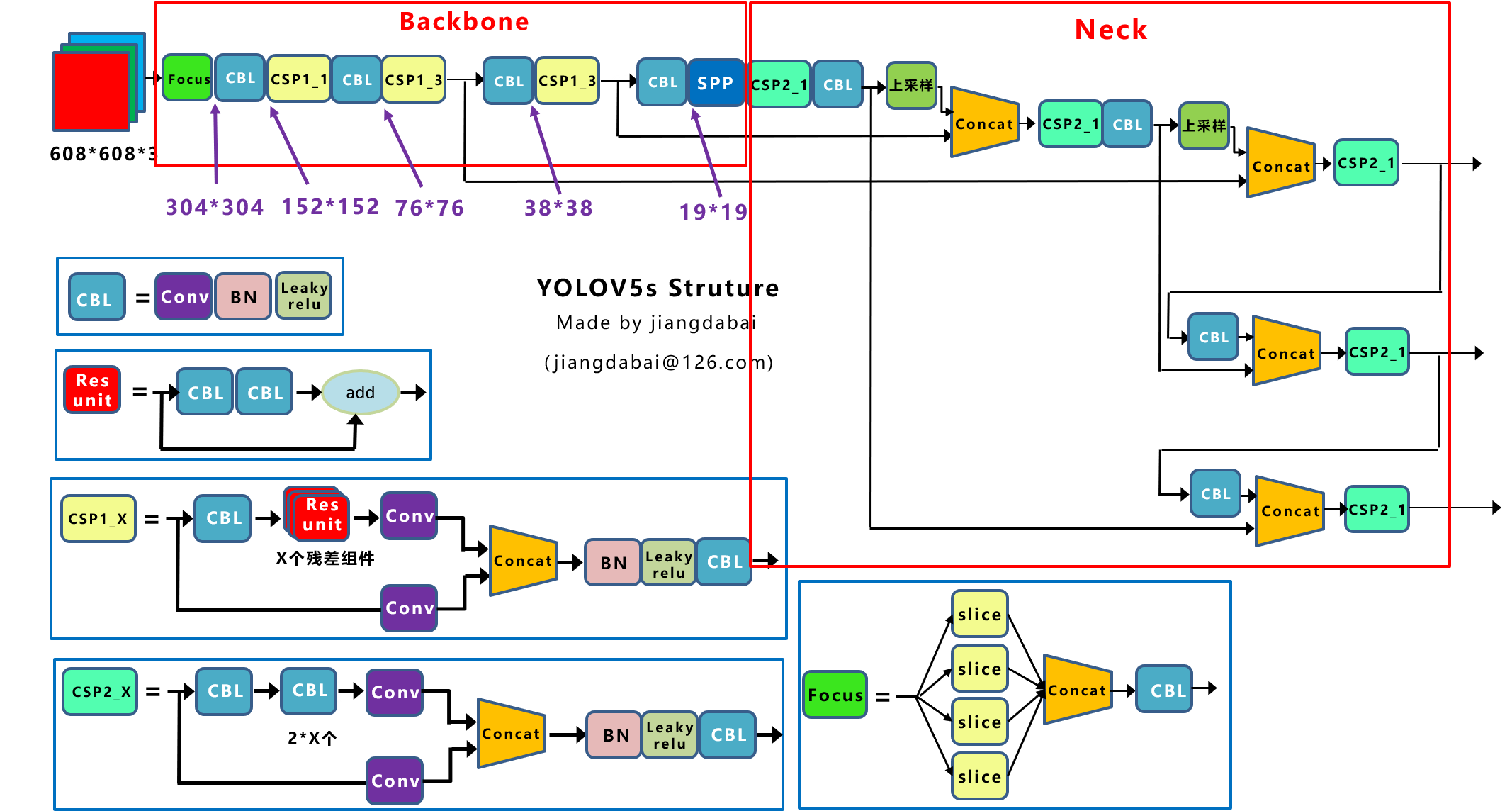
上面所有模块基本都讲过了,大部分在V4那篇文章,右边Neck就是PAN,在FPN基础上再做一次。
模型文件:可以对比一下,其实差不多,是不是比YOLOV3看起来舒服太多了
# parameters nc: 2 # number of classes 控制模型深度和通道 depth_multiple: 0.33 # model depth multiple #下面的number*0.33 width_multiple: 0.50 # layer channel multiple #下面的channel*0.33 # anchors 就是聚类的九个框 anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 backbone backbone: # [from, number, module, args] # -1代表是一个输出,做了number次数,模块名,参数(通道数,卷积核,步长) [[-1, 1, Focus, [64, 3]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, BottleneckCSP, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 9, BottleneckCSP, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, BottleneckCSP, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 1, SPP, [1024, [5, 9, 13]]], [-1, 3, BottleneckCSP, [1024, False]], # 9 ] # YOLOv5 head 就是FPN + PAN head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, BottleneckCSP, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
4.模型可视化
- 可视化工具
配置好netron,详情:https://github.com/lutzroeder/netron 网页版 - 安装好onnx,pip install onnx即可
- 转换得到onnx文件,脚本原始代码中已经给出(/models/export.py)
- 打开onnx文件进行可视化展示(.pt文件展示效果不如onnx)
点击放大lol
三、YOLO-V5模型梳理
1.整体模型图
可以理解为输入前BOF(数据处理部分)+ BOS(模型改进部分)

2.整体流程
- 输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
- Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
- Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
3.YOLOv5基础组件
- CBL-CBL模块由Conv+BN+Leaky_relu激活函数组成
- Res unit-借鉴ResNet网络中的残差结构,用来构建深层网络,CBL是残差模块中的子模块
- CSP1_X-借鉴CSPNet网络结构,该模块由CBL模块、Res unint模块以及卷积层、Concate组成而成
- CSP2_X-借鉴CSPNet网络结构,该模块由卷积层和X个Res unint模块Concate组成而成
- Focus,Focus结构首先将多个slice结果Concat起来,然后将其送入CBL模块中。
- SPP-采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合
四、代码文件讲解
1.项目目录结构

2.目录解释
- github是存放关于github上的一些“配置”的,这个不重要,我们可以不管它。
- data文件夹主要是存放一些超参数的配置文件(如.yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称;还有一些官方提供测试的图片,YOLOv5 有大约 30 个超参数用于各种训练设置。
- models是模型文件夹。里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测速度分别都是从快到慢,但是精确度分别是从低到高。代码 下载模型
- runs是我们运行的时候的一些输出文件。每一次运行就会生成一个exp的文件夹。
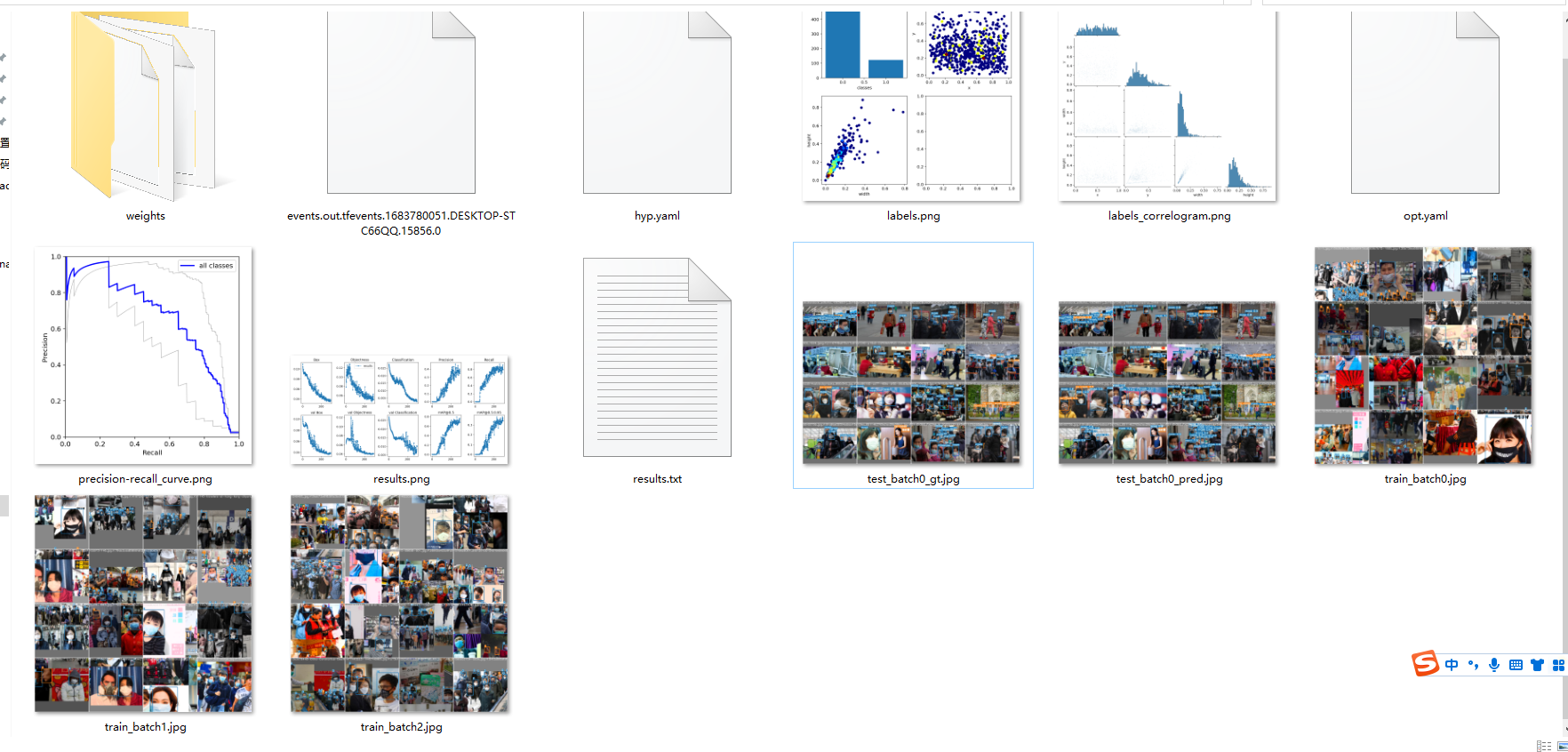
detect # 测试模型,输出图片并在图片中标注出物体和概率 train # 训练模型,输出内容,模型(最好、最新)权重、混淆矩阵、F1曲线、超参数文件、P曲线、R曲线、PR曲线、结果文件(loss值、P、R)等expn expn # 第n次实验数据 confusion_matrix.png # 混淆矩阵 P_curve.png # 准确率与置信度的关系图线 R_curve.png # 精准率与置信度的关系图线 PR_curve.png # 精准率与召回率的关系图线 F1_curve.png # F1分数与置信度(x轴)之间的关系 labels_correlogram.jpg # 预测标签长宽和位置分布 results.png # 各种loss和metrics(p、r、mAP等,详见utils/metrics)曲线 results.csv # 对应上面png的原始result数据 hyp.yaml # 超参数记录文件 opt.yaml # 模型可选项记录文件 train_batchx.jpg # 训练集图像x(带标注) val_batchx_labels.jpg # 验证集图像x(带标注) val_batchx_pred.jpg # 验证集图像x(带预测标注) weights # 权重 best.pt # 历史最好权重 last.pt # 上次检测点权重 labels.jpg # 4张图, 4张图,(1,1)表示每个类别的数据量,(1,2)真实标注的 bounding_box(2,1) 真实标注的中心点坐标,(2,2)真实标注的矩阵宽高
- utils工具文件夹。存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
3.如何训练自己的数据
https://public.roboflow.com/object-detection/mask-wearing/4/download/yolov5pytorch

例如口罩数据集下载,选择yolov5pytorch格式,直接就能用,把它放在yolo_v5同级目录
pycharm 配置参数 --data ../MaskDataSet/data.yaml --epochs 300 --weights '' --cfg models/yolov5s.yaml --batch-size 16
# data.yaml文件包含数据文件索引 train: ../MaskDataSet/train/images val: ../MaskDataSet/valid/images nc: 2 names: ['mask', 'no-mask']
结果:

日志可视化:切换运行环境的日志路径下,也就是
tensorboard --logdir runs/


相关文章

我的公众号
微信扫一扫
评论