


一、前言
YOLOv4(You Only Look Once version 4)是一种先进的目标检测系统,于2020年推出。它是对之前版本YOLO的改进,后者是一种广泛使用的基于深度学习的目标检测算法。YOLOv4基于深度卷积神经网络,可以高精度实时检测图像中的目标。它使用单个神经网络,输入图像并输出所有目标的边界框和类别概率。YOLOv4相对于其前身YOLOv3的一些主要改进包括:
- 增加网络的深度和宽度,以获得更好的特征表示
- 使用先进的数据增强技术,以提高模型的泛化能力
- 整合多种先进的目标检测技术,如空间金字塔池化、Mish激活函数和交叉阶段部分网络。
YOLOv4是一个开源项目,在GitHub上免费提供。它已成为许多计算机视觉应用程序的流行选择,包括自动驾驶汽车、安全系统和监控系统。论文 ,代码
二、YOLO-V4
1.概述
虽然作者换了,但精髓没变!整体看还是那个味,细还是他细!
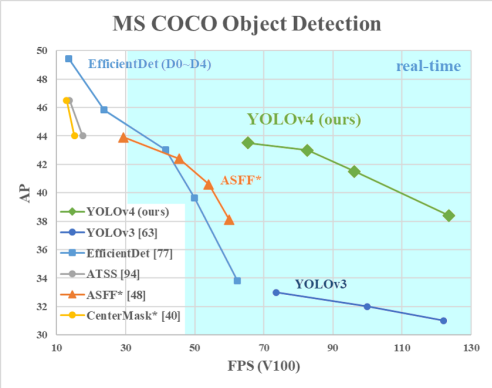
V4贡献:亲民政策,单GPU就能训练的非常好,接下来很多小模块都是这个出发点,两大核心方法,从数据层面和网络设计层面来进行改善消融实验,感觉能做的都让他给做了,这工作量不轻全部实验都是单GPU完成,不用太担心设备了。下面逐一介绍这些小模块
2.Bag of freebies(BOF)
只增加训练成本,但是能显著提高精度,并不影响推理速度,数据增强:调整亮度、对比度、色调、随机缩放、剪切、翻转、旋转,网络正则化的方法:Dropout、Dropblock等,类别不平衡,损失函数设计,数据增强加了很多操作,如下:
- Mosaic data augmentation
方法很简单,参考CutMix然后四张图像拼接成一张进行训练,现在一个batch相当于以前4个batch
方法都是围绕单GPU运行,就是要快

- Random Erase:用随机值或训练集的平均像素值替换图像的区域Hide and Seek:根据概率设置随机隐藏一些补丁

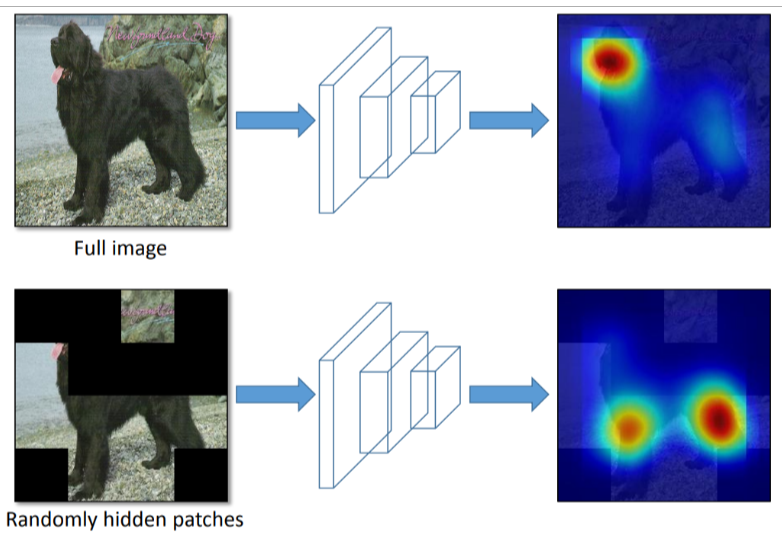
- Self-adversarial-training(SAT)引入噪音点来增加难度

- DropBlock (之前的dropout是随机选择点,现在吃掉一个区域)

- Label Smoothing神经网络最大的缺点:自觉不错(过拟合),让它别太自信,标签01改为,0.95,0.05,效果
使用之后效果分析(右图):簇内更紧密,簇间更分离

- CIOU损失
什么是CIOU,从IOU开始

没有相交则IOU=0无法梯度计算,相同的IOU却反映不出实际情况到底咋样
引入GIOU损失
引入了最小封闭形状C(C可以把A,B包含在内)在不重叠情况下能让预测框尽可能朝着真实框前进


引入DIOU损失(如果预测框在真实框里面)
其中分子计算预测框与真实框的中心点欧式距离d,分母是能覆盖预测框与真实框的最小BOX的对角线长度c,直接优化距离,速度更快,并解决GIOU问题
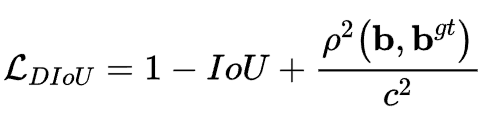

优化:CIOU损失
损失函数必须考虑三个几何因素:重叠面积,中心点距离,长宽比,其中α可以当做权重参数
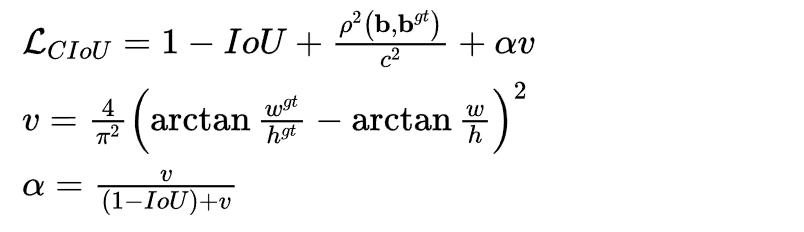
- DIOU-NMS
之前使用NMS来决定是否删除一个框,现在改用DIOU-NMS,不仅考虑了IoU的值,还考虑了两个Box中心点之间的距离,其中M表示高置信度候选框,Bi就是遍历各个框跟置信度高的重合情况
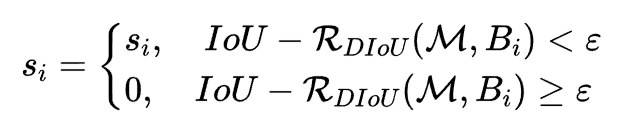
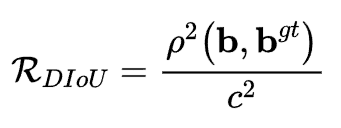
- SOFT-NMS在目标检测中,NMS用于通过选择具有最高置信度得分的框来删除冗余的边界框。然而,当检测算法产生具有类似置信度分数的重叠框时,这有时会导致重要边界框的消除。
Soft-NMS通过对重叠框的置信度分数应用衰减函数来解决这个问题,这个函数基于其与最高得分框之间的重叠程度降低较低得分框的得分。其思想是保留较低得分框的信息,同时优先考虑最高得分框。这使得Soft-NMS在重叠框的情况下更加容忍,并有助于提高目标检测的准确性。

3.Bag of specials(BOS)
增加稍许推断代价,但可以提高模型精度的方法,网络细节部分加入了很多改进,引入了各种能让特征提取更好的方法,注意力机制,网络细节设计,特征金字塔等,你能想到的全有,读折一篇相当于把今年来部分优秀的论文又过了一遍
- SPPNet(Spatial Pyramid Pooling)
V3中为了更好满足不同输入大小,训练的时候要改变输入数据的大小,V4在最后的卷积层和全连接层之间加入SPP层。具体做法是,在conv层得到的特征图是256层,每层都做一次spatial pyramid pooling。先把每个特征图分割成多个不同尺寸的网格,比如网格分别为44、22、11,然后每个网格做max pooling,这样256层特征图就形成了16x256,4x256,1x256维特征,他们连起来就形成了一个固定长度的特征向量,将这个向量输入到后面的全连接层。

- CSPNet(Cross Stage Partial Network)
CSPNet中的跨阶段部分连接将网络的特征图分成两部分,其中一部分通过多个卷积层进行处理,而另一部分则通过较少的层进行处理。两条路径的输出然后使用连接操作进行组合,生成的特征图再由另一组卷积层进行处理。这种方法允许不同阶段之间更好的信息流动,从而提高准确性并降低计算成本。

- CBAM
它是一种用于图像分类任务的神经网络模块。CBAM模块结合了空间和通道注意机制,可以选择性地强调图像中的重要特征,同时抑制不相关的特征。
空间注意机制通过计算关注度映射来强调特征图的空间维度,突出最具信息量的区域。而通道注意机制则通过计算关注度映射来强调特征图的通道维度,突出最重要的通道。
通过结合这两种注意机制,CBAM模块能够有选择地增强图像的信息特征并抑制不相关的特征。这导致在各种图像分类任务(如对象识别、场景分类和图像检索)中表现出更好的性能。

Channel Attention Module(CAM)
将输入的特征图F(H×W×C)分别经过基于width和height的global max pooling(全局最大池化)和global average pooling(全局平均池化),得到两个1×1×C的特征图,接着,再将它们分别送入一个两层的神经网络(MLP),第一层神经元个数为 C/r(r为减少率),激活函数为 Relu,第二层神经元个数为 C,这个两层的神经网络是共享的。而后,将MLP输出的特征进行基于element-wise的加和操作,再经过sigmoid激活操作,生成最终的channel attention feature,即M_c。最后,将M_c和输入特征图F做element-wise乘法操作,生成Spatial attention模块需要的输入特征。
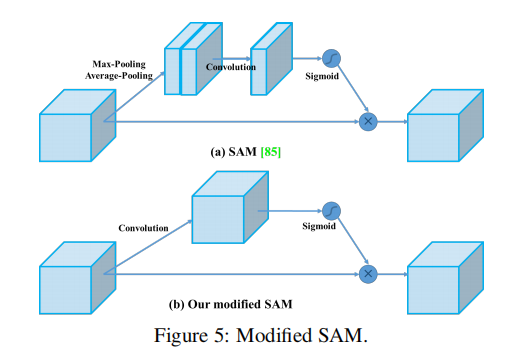
Spatial attention module(SAM)
将输入的特征图F(H×W×C)分别经过基于width和height的global max pooling(全局最大池化)和global average pooling(全局平均池化),得到两个1×1×C的特征图,接着,再将它们分别送入一个两层的神经网络(MLP),第一层神经元个数为 C/r(r为减少率),激活函数为 Relu,第二层神经元个数为 C,这个两层的神经网络是共享的。而后,将MLP输出的特征进行基于element-wise的加和操作,再经过sigmoid激活操作,生成最终的channel attention feature,即M_c。最后,将M_c和输入特征图F做element-wise乘法操作,生成Spatial attention模块需要的输入特征。
YOLOV4中的Spatial attention module(去除池化,直接卷积)
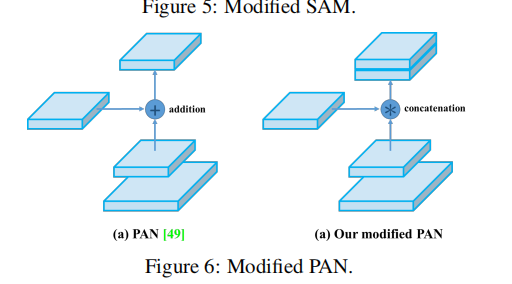
- PAN(Path Aggregation Network)
PAN通过一种保留空间和语义信息的方式,将不同层次的特征结合起来。这是通过一种自上而下和自下而上的特征聚合过程实现的。就是融合FPN(a),加了自下而上的路径,p2已经有了全局信息

YOLOV4中的Spatial attention module(并不是加法,而是拼接)
- 激活函数Mish

Relu有点太绝对了,Mish更符合实际,但是计算量确实增加了,效果会提升
公式: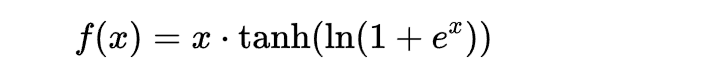
- eliminate grid sensitivity
坐标回归预测值都在0-1之间,如果在grid边界怎么表示?此时就需要非常大的数值才可以达到边界,为了缓解这种情况可以在激活函数前加上一个系数(大于1的)

4.整体网络架构
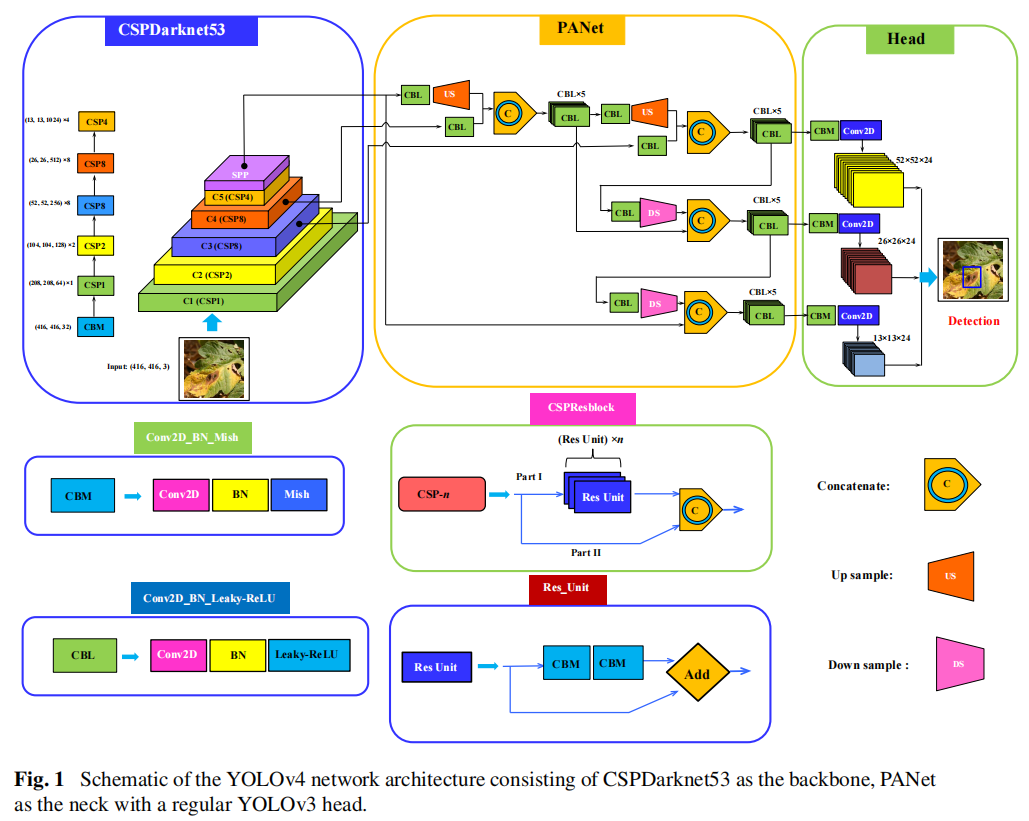


评论